Gemma 4 vs Qwen 3.5: 30-Question Blind Eval Breakdown | AI Bytes
0% read
Gemma 4 vs Qwen 3.5: 30-Question Blind Eval Breakdown
Comparisons
Gemma 4 vs Qwen 3.5: 30-Question Blind Eval Breakdown
A community blind eval pits Gemma 4 31B, Gemma 4 26B-A4B, and Qwen 3.5 27B against each other across 30 questions. Qwen wins more matchups, but Gemma leads on consistency. The numbers tell a complicated story.
April 10, 2026
8 min read
203 views
Updated July 15, 2026
The model with the highest win rate had the lowest average score.
That single contradiction tells you everything about the current state of open-source LLMs in the ~30B parameter range. A community member on r/LocalLLaMA recently ran a 30-question blind evaluation pitting three models against each other: Google's Gemma 4 31B (dense), Gemma 4 26B-A4B (MoE variant), and Alibaba's Qwen 3.5 27B. Claude Opus 4.6 served as judge, scoring each response independently on a 0-10 rubric. And the results make the Gemma 4 vs Qwen 3.5 comparison genuinely complicated.
Quick Verdict: Gemma 4 31B vs Qwen 3.5 27B
Gemma 4 31B is the better choice for most users. It never errored out, scored a consistent 8.82 average across all 30 questions, and dominated communication tasks. Qwen 3.5 27B is the stronger model on individual questions, but its 10% failure rate makes it unreliable for production workloads.
If you need reliability above all else, pick Gemma 4 31B. It won 40% of matchups, held steady across every category, and finished all 30 evaluations without a single error.
If you want peak performance and can tolerate occasional failures, Qwen 3.5 27B won 46.7% of head-to-head matchups. When its three zero-score format failures are excluded, its adjusted average hits ~9.08. That's the highest of all three models by a wide margin.
If hardware constraints matter most, Gemma 4 26B-A4B matches the dense 31B on average score while activating only ~3.8B parameters per token. Promising, but it errored on 2 of 30 questions.
30 questions across 5 categories (6 per category): code, reasoning, analysis, communication, and meta-alignment
Blind evaluation: all three models answered identical questions with the same temperature and no system prompt differences
Independent scoring: Claude Opus 4.6 judged each response on a 0-10 absolute scale using a structured rubric (not comparative "which is better" ranking)
Single judge: the tester prioritized consistency over multi-judge noise, citing a 99.9% parse rate in prior batches
Total cost: $4.50 for the entire evaluation run
The single-judge approach is a fair criticism vector. Positional bias is a known issue with LLM-as-judge setups. But with absolute scoring and near-perfect parse reliability, it's a reasonable tradeoff for a community benchmark.
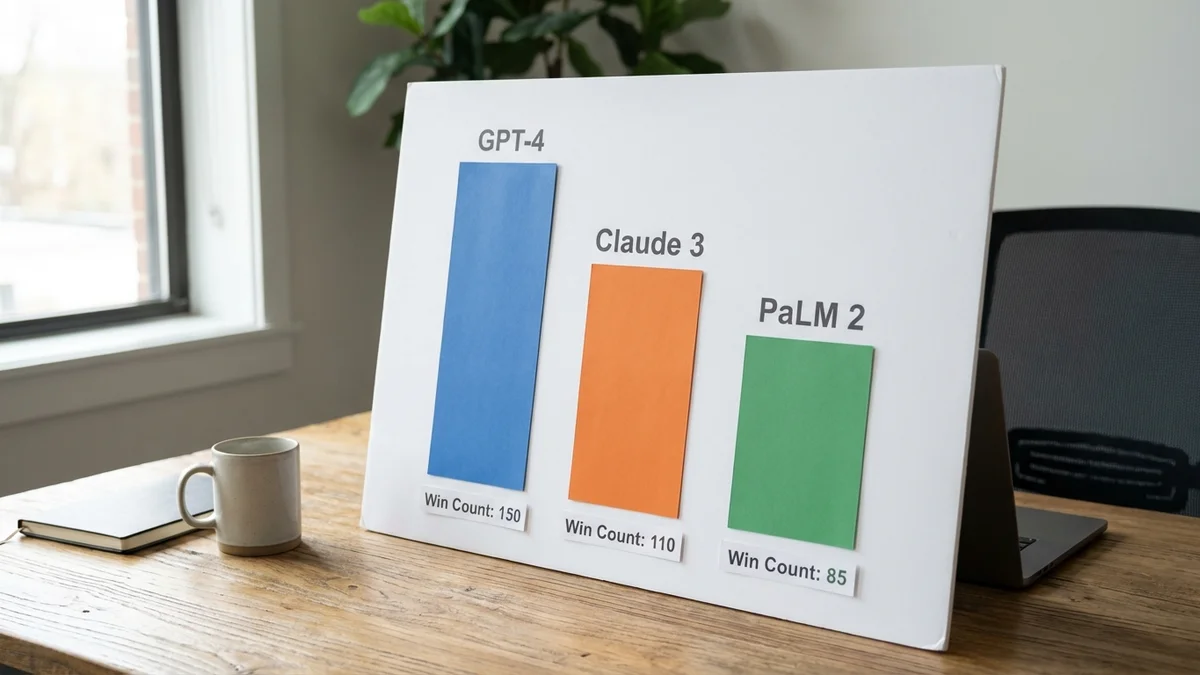
Head-to-Head Win Counts
Model
Wins
Win %
Qwen 3.5 27B
14
46.7%
Gemma 4 31B
12
40.0%
Gemma 4 26B-A4B
4
13.3%
Qwen takes almost half the matchups. Not bad for a model that's about to get dragged by its own average score.
Average Scores Tell a Different Story
Model
Avg Score
Evaluations Completed
Gemma 4 31B
8.82
30/30
Gemma 4 26B-A4B
8.82
28/30
Qwen 3.5 27B
8.17
30/30
The model with the most wins posted the lowest average score. Reliability and peak performance are different things.
The paradox is obvious. Qwen wins nearly half the individual matchups but posts the lowest average by a wide margin. Both Gemma variants tie at 8.82, despite the MoE version only completing 28 of 30 evaluations.
Category-by-Category Breakdown
The aggregate numbers obscure what's actually happening. Each model has distinct strengths, and the Gemma 4 vs Qwen 3.5 comparison looks very different depending on what you're asking the model to do.
Code
Tied at 3 wins each for Gemma 4 31B and Qwen 3.5 27B. The MoE variant didn't pick up a single code win. If coding is your primary use case, both the dense Gemma and Qwen are solid options. We tested this more thoroughly in our Qwen3.5 vs Gemma4 coding comparison.
Reasoning
Qwen 3.5 27B dominates with 5 of 6 wins. This is where Qwen really separates itself. For math, logic, and multi-step problem solving, it's clearly the stronger choice in this weight class.
Analysis
Another Qwen stronghold at 4 of 6 wins. Tasks requiring data interpretation, pattern recognition, and information synthesis favor Qwen's architecture.
Communication
Gemma 4 31B takes this category with 5 of 6 wins. Writing quality, tone matching, and clear explanations are where the dense Gemma excels. If you're building a chatbot or writing assistant, this is your model.
Meta-Alignment
A perfect three-way split at 2-2-2. None of the models showed a meaningful edge in alignment-related tasks.
Why Qwen Wins More But Scores Less
So Qwen 3.5 27B wins more questions and produces the highest-quality individual answers. Why not just declare it the winner?
Because it scored 0.0 on three questions: CODE-001, REASON-004, and ANALYSIS-017. The tester suspects format failures or outright refusals rather than genuinely terrible answers. That's a 10% failure rate on a 30-question test.
Strip out those zeros and Qwen's average jumps from 8.17 to approximately 9.08. That would make it the best performer by a significant margin. But you can't just hand-wave away failures in production. A model that gives brilliant output nine times out of ten and then garbles or refuses the tenth is a real problem for automated pipelines, API endpoints, and any workflow where manual review isn't practical.
A model that gives brilliant output nine times out of ten and then garbles the tenth is a real problem for automated pipelines.
For interactive use where retrying is trivial? Qwen 3.5 27B is arguably the best model in this comparison. For unattended, fire-and-forget workloads? That failure rate is pretty hard to accept.
Gemma 4 26B-A4B: The MoE Efficiency Angle
The Mixture-of-Experts variant is the most interesting model in this test, even though it finished last on win count. Consider what it actually achieved: it matched the dense 31B's 8.82 average score while activating only about 3.8 billion parameters per forward pass (hence the "A4B" in the name). That's roughly 8x less compute per token than the full 31B.
But it errored out on 2 of 30 questions entirely, completing only 28 evaluations. When it worked, it performed just as well as its dense sibling. When it didn't, it produced nothing at all.
This is a familiar pattern with early MoE releases. The expert routing mechanism occasionally fails on edge cases that dense architectures handle more gracefully. If Google tightens up reliability in future updates (and they likely will), the 26B-A4B could become the default pick for hardware-constrained setups. For now, it's a "watch this space" situation.
VRAM and Hardware Requirements
Running these models locally means thinking about your GPU budget. (If you're new to local inference, our guide to running Llama 4 locally covers the basics.) At FP16 precision:
With GGUF quantization at Q4_K_M, all three drop into the 15-18 GB range. That makes them runnable on a single RTX 4090 (24 GB) or dual RTX 3090s. The MoE variant's lower active parameter count means faster inference even at the same quantization level, which partly offsets its reliability issues.
One other detail from the original evaluation: the tester reported that Gemma 4 31B had "absurdly long response times" compared to the other two models. If latency matters for your use case, that's worth benchmarking on your specific hardware.
When to Choose Each Model
Pick Gemma 4 31B if:
Reliability is non-negotiable; zero errors across all 30 questions
Communication and writing tasks are your priority
You want a consistent all-rounder for production use
You can tolerate slower inference speeds
Pick Qwen 3.5 27B if:
Reasoning and analysis are your primary tasks
You want the highest possible ceiling per individual response
You're using it interactively and can retry on failures
You're hardware-constrained and want MoE efficiency
Dense-model quality at a fraction of the compute appeals to you
You're comfortable with occasional errors while the model matures
Context: How ~30B Open-Source Models Compare to Frontier
These models play in a different league than frontier systems. Frontier models like Claude Opus 4.6 and GPT-4.1 still outperform these open-source models on standard benchmarks by a significant margin, as you'd expect given the difference in scale and training resources.
But the whole point of running local models is trading some quality for zero marginal cost and full data privacy. An 8.82 average on a 10-point scale (with questions spanning code, reasoning, analysis, communication, and alignment) suggests these ~30B models are genuinely capable for a wide range of tasks. Not frontier-level, but pretty solid for running on your own hardware.
Final Verdict
Qwen 3.5 27B wins on raw talent. Gemma 4 31B wins on reliability. And which one you should use depends entirely on your tolerance for failure.
For most local LLM users running models through Ollama, llama.cpp, or vLLM, the practical recommendation is Gemma 4 31B. Consistency matters more than peak performance in almost every real production workflow. You'd rather get a B+ answer every time than an A+ answer 90% of the time with dead air the other 10%.
But if you're doing research, creative exploration, or anything where you manually review outputs, Qwen 3.5 27B's reasoning dominance is hard to ignore. Not gonna lie, an adjusted 9.08 average (excluding format failures) is seriously impressive for a 27B parameter model.
And keep watching Gemma 4 26B-A4B. Matching its dense sibling's quality at a fraction of the compute is exactly the efficiency story that makes MoE architectures worth paying attention to. It just needs to stop erroring out first.
Yes, with quantization. At full FP16 precision, Gemma 4 31B needs ~62 GB of VRAM, which won't fit on any consumer card. But at Q4_K_M quantization via llama.cpp or Ollama, it drops to roughly 17-18 GB, fitting comfortably on an RTX 4090's 24 GB. You'll lose some quality compared to FP16, but for most tasks the difference is minimal. Q5_K_M is also feasible at around 21 GB if you want slightly better fidelity.
How do I reduce Qwen 3.5 27B's failure rate for automated workflows?
The 10% failure rate in the blind eval appears to stem from format failures and refusals, not quality issues. You can mitigate this by adding retry logic with a 2-3 attempt limit, using structured output enforcement (like JSON mode or grammar-constrained generation in llama.cpp), and including explicit format instructions in your system prompt. Some users report that slightly higher temperatures (0.7-0.8) reduce refusal rates on edge-case prompts.
Is Gemma 4 26B-A4B actually faster than Gemma 4 31B in practice?
It should be, since MoE models only activate a subset of parameters per token. The 26B-A4B activates roughly 3.8B parameters per forward pass compared to the full 31B in the dense model. In practice, this means significantly faster token generation, especially on GPUs with limited memory bandwidth. However, MoE models have higher memory requirements for loading all experts, so the speed advantage is most noticeable during generation rather than initial loading.
Does using Claude Opus 4.6 as a judge introduce bias toward certain response styles?
It's a valid concern. LLM judges tend to prefer responses that match their own training distribution, which could favor verbose, well-structured answers over terse but correct ones. The original tester mitigated this by using absolute 0-10 scoring with a structured rubric rather than comparative ranking. Multi-judge setups with different models (like using Gemini or GPT-4.1 as secondary judges) can help detect bias, though they add cost and complexity.
How does Gemma 4 31B compare to Llama 4 Maverick for local inference?
They target different use cases. Llama 4 Maverick is a much larger model with up to 1 million tokens of context, designed more for cloud deployment than local use. Gemma 4 31B is specifically sized for consumer and prosumer hardware at the ~30B parameter sweet spot. For a single-GPU local setup, Gemma 4 31B is far more practical. If you have multi-GPU infrastructure and need long-context support, Llama 4 Maverick is worth evaluating instead.