DeepSeek vs Llama 4: Which Open Source LLM Wins? | AI Bytes
0% read
DeepSeek vs Llama 4: Which Open Source LLM Wins?
Comparisons
DeepSeek vs Llama 4: Which Open Source LLM Wins?
DeepSeek R1 dominates reasoning benchmarks while Llama 4 Maverick offers a 1M-token context window. We break down benchmarks, architecture, pricing, and use cases to help you pick the right open source LLM.
April 18, 2026
9 min read
317 views
Updated July 19, 2026
Two open source AI models are outperforming most proprietary systems right now, and they're both free to download. DeepSeek R1 scores 90.8% on MMLU, rivaling proprietary models that charge premium API rates. Llama 4 Maverick offers a million-token context window that most commercial alternatives can't touch. The question isn't whether open source LLMs are good enough anymore. It's which one deserves your GPU time.
Both DeepSeek and Llama 4 use mixture-of-experts (MoE) architectures, both are free to download, and both crush older proprietary models on most benchmarks. But they're built for different jobs, and choosing wrong means wasting compute or leaving performance on the table.
DeepSeek vs Llama 4 at a Glance
Before getting into the details, this comparison table covers the essential specs.
Feature
DeepSeek (R1 / V3)
Llama 4 (Maverick / Scout)
Developer
DeepSeek
Meta
Total Parameters
671B (V3/R1)
~400B (Maverick) / 109B (Scout)
Active Parameters
~37B per token
~17B per token
Context Window
128K tokens
1M (Maverick) / 10M (Scout)
Architecture
Mixture-of-Experts
Mixture-of-Experts
Reasoning Mode
Yes (R1 chain-of-thought)
No
License
MIT (R1) / DeepSeek License (V3 model weights)
Llama Community License
Multimodal
Text only (V3/R1)
Text + Image
The biggest spec difference? DeepSeek brings more active parameters per token (37B vs 17B) and a dedicated reasoning model. Llama 4 counters with a dramatically larger context window and lower hardware requirements during generation.
Architecture and Model Design
Both model families use mixture-of-experts, but the design philosophies diverge significantly.
DeepSeek V3 runs 671 billion total parameters with roughly 37 billion active per forward pass. That's a substantial amount of active compute, and it shows in benchmark scores. The model uses a fine-grained expert selection mechanism that routes tokens to the most relevant expert modules during inference.
DeepSeek R1 builds on V3's foundation by adding reinforcement learning-trained chain-of-thought reasoning. Instead of just predicting the next token, R1 generates an internal reasoning trace before producing its final answer. You can watch it work through problems step by step. This approach (pioneered in various forms by OpenAI's o1 and o3) makes a huge difference on tasks requiring multi-step logic.
Llama 4 Maverick takes a leaner approach: approximately 400 billion total parameters with roughly 17 billion active per token. Meta optimized for efficiency and context length rather than raw reasoning depth. The lower active parameter count means faster inference and significantly lower memory overhead during token generation. And that efficiency gap matters more than you might expect at scale.
Your bottleneck determines your winner: DeepSeek trades compute for thinking power, Llama 4 trades depth for speed and context length.
DeepSeek's approach gives you more thinking power per token at the cost of heavier compute. Llama 4's approach gives you speed and the ability to process enormous documents.
Benchmark Performance
This is where DeepSeek currently has a clear edge in verified, independent numbers. (For a broader look at how all major LLMs stack up, see our 2026 LLM benchmark roundup.)
Reasoning and Knowledge
Based on DeepSeek's published benchmarks, R1 scores 90.8% on MMLU (self-reported), putting it in the same tier as top proprietary models. On GPQA Diamond, a tough graduate-level science benchmark, R1 hits 71.5% (self-reported). DeepSeek V3 scores 89.3% on GSM8K math problems (8-shot, self-reported).
For Llama 4 Maverick, independent benchmark results across these specific tests haven't been as widely consolidated. Meta shared competitive numbers at launch, but third-party verification on all standard benchmarks is still catching up in early 2026. This is worth flagging: DeepSeek has simply been in the wild longer, giving researchers more time to evaluate it independently.
Coding Benchmarks
DeepSeek V3's chat model scores 82.6% on HumanEval-Mul, a multilingual coding variant (self-reported). GPT-4o scores 90.2% on standard HumanEval. On SWE-bench Verified, DeepSeek R1 hits 49.2% with appropriate scaffolding (self-reported).
Not gonna lie, those are impressive numbers for open source models. You're getting within striking distance of the best proprietary systems without paying a cent in API fees.
Math Performance
DeepSeek R1 scores 97.3% on MATH-500 (self-reported), putting it ahead of OpenAI's o1 (94.8% on MATH) and competitive with the best proprietary reasoning models. For a free, open-weight model, scoring in the same tier as OpenAI's top reasoning systems is exceptional.
The bottom line on benchmarks: DeepSeek has more verified third-party data, and the numbers are genuinely strong. Llama 4 Maverick likely performs competitively on similar tests, but the community hasn't consolidated as much independent data yet.
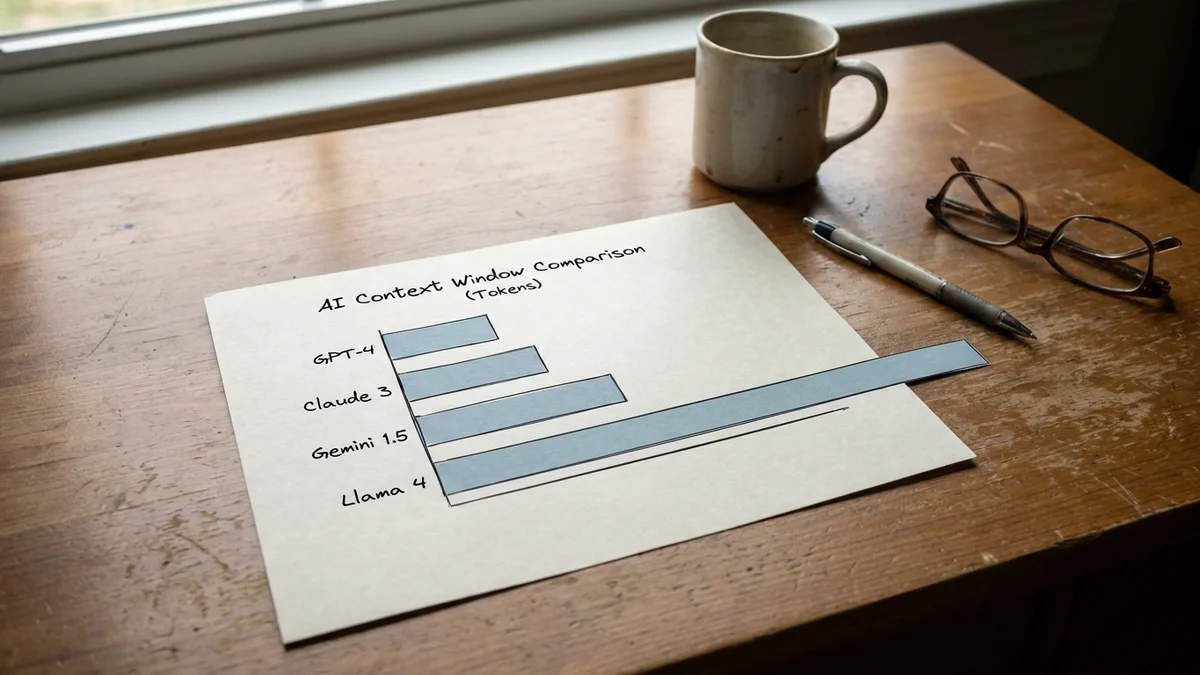
Context Window: Llama 4's Killer Feature
In the DeepSeek vs Llama 4 context window comparison, if context length is your priority, this comparison isn't even close. Llama 4 Maverick supports 1 million tokens of context. Llama 4 Scout stretches to a staggering 10 million. DeepSeek V3 and R1 top out at 128,000 tokens.
That's roughly an 8x difference between Maverick and DeepSeek. If your work involves processing entire codebases, lengthy legal documents, or multi-hour meeting transcripts, Llama 4 wins by default. If you want to test this yourself, our guide to running Llama 4 locally walks through the full setup.
A million tokens translates to roughly 750,000 words. That's multiple books, dozens of research papers, or a substantial codebase fed in as a single prompt. For retrieval-augmented generation (RAG) workflows, a larger context window means you can include more relevant context without complex chunking and retrieval strategies.
But context length isn't everything. Longer contexts mean higher memory usage during inference and potentially slower processing. There's also the well-documented "lost in the middle" problem, where models sometimes struggle to recall information buried deep in very long contexts. The real question is whether you actually need a million tokens, or whether 128K covers your use case.
For most applications (chatbots, coding assistants, standard Q&A), 128K is plenty. For document analysis, legal review, codebase understanding, or research synthesis, Llama 4's context advantage is a genuine differentiator.
Pricing and Self-Hosting
When comparing DeepSeek vs Llama 4 on cost, both models are free to download and run. The real cost is hardware.
DeepSeek V3's 671B parameters require substantial VRAM even with quantization. You're looking at a multi-GPU setup regardless of precision level. Running the full model comfortably means serious cloud spend or dedicated on-premise hardware.
Llama 4 Maverick's ~400B parameters with only 17B active per token means lower compute per generation step, but you still need enough memory to load the full model weights. The advantage shows up in generation speed and throughput: fewer active parameters means faster tokens per second once everything is loaded.
For API access through third-party providers, both models are available on platforms like Together AI, Fireworks AI, and several others. DeepSeek also offers its own hosted API at competitive rates.
The cost savings over proprietary alternatives are significant either way. Whether you self-host or use a third-party API, you'll pay substantially less than comparable proprietary model pricing. That's the whole point of open source.
Reasoning: DeepSeek R1's Strongest Advantage
This is where the two model families diverge most sharply, and it's the section you should pay closest attention to if your use case involves analytical work.
DeepSeek R1 is a reasoning model. It uses reinforcement learning to develop explicit chain-of-thought capabilities, generating an internal reasoning trace before producing its final answer. You can literally see it work through math problems, debug code step by step, and untangle logical puzzles. That visible thinking process isn't just a party trick; it produces measurably better results on complex tasks.
Llama 4 Maverick is a standard autoregressive model. It's capable and fast, but it generates answers directly without a dedicated thinking phase. R1 shows its work; Maverick jumps straight to the answer.
On tasks requiring multi-step reasoning (complex math, formal logic, tricky coding problems), DeepSeek R1 consistently outperforms standard models. On straightforward tasks like summarization, translation, or simple Q&A, the difference between them shrinks considerably.
If you're building an AI coding assistant or a technical analysis tool, DeepSeek R1 is the better foundation. If you're building a content generation pipeline or a conversational agent, Llama 4 Maverick's speed advantage matters more than reasoning depth.
Ecosystem and Community Support
On ecosystem support, the DeepSeek vs Llama 4 gap is significant. Meta's Llama ecosystem is enormous. According to Meta, Llama models have been downloaded hundreds of millions of times, with extensive fine-tuned variants, community tooling, and deployment guides. Most ML frameworks and inference engines support Llama models natively: vLLM, TGI, Ollama, llama.cpp all have solid Llama support. (We benchmarked Ollama, LM Studio, and llama.cpp head-to-head if you want speed comparisons.)
DeepSeek has built an impressive community in a shorter timeframe. The models are widely available through HuggingFace and most major inference platforms. But the ecosystem is younger. You'll find fewer fine-tuned variants, fewer production deployment guides, and less battle-tested tooling compared to Llama.
One practical consideration worth mentioning: DeepSeek is developed by a Chinese AI lab, and some organizations have internal policies about model provenance. This shouldn't drive technical decisions, but it's a reality for certain enterprise deployments.
On licensing, DeepSeek R1 uses the MIT license for both code and model weights, which is about as permissive as open source gets. DeepSeek V3's code is MIT-licensed, but its model weights are under a custom DeepSeek License Agreement. Meta's Llama uses a community license that's generous but comes with usage restrictions above certain user thresholds (historically 700 million monthly active users). For the vast majority of teams, both licenses work fine. But if maximum licensing flexibility matters, DeepSeek R1 has the edge with its full MIT license.
When to Choose DeepSeek
Pick DeepSeek if you need:
Strong reasoning and chain-of-thought: R1 is purpose-built for analytical thinking
Math and science tasks: 97.3% on MATH-500 (self-reported) and 90.8% on MMLU are hard to beat in open source
Coding assistance: Strong coding benchmark scores with solid SWE-bench performance
Maximum licensing freedom: MIT license (R1) gives you total flexibility
Verified benchmark performance: More independent third-party evaluation data available
DeepSeek R1 is the model to beat for complex reasoning, code generation, and analytical tasks.
When to Choose Llama 4
Pick Llama 4 if you need:
Massive context windows: 1M tokens (Maverick) or 10M tokens (Scout)
Lower inference cost per token: 17B active parameters means faster, cheaper generation
Document processing at scale: Entire codebases, legal documents, or research papers in one pass
Mature ecosystem: Better tooling support, more fine-tuned variants, broader community resources
Llama 4 is the stronger choice for production deployments where context length, speed, and ecosystem maturity take priority.
The Final Verdict
The question isn't which model is "better" — it's which bottleneck you're solving for.
There's no single winner here, and anyone who tells you otherwise is oversimplifying a real engineering decision.
For reasoning-intensive work (coding, math, science, logic): DeepSeek R1 wins. The chain-of-thought reasoning gives it a measurable edge that Llama 4 can't replicate with standard inference. Build your developer tools and analytical systems on DeepSeek.
For context-heavy work (document analysis, RAG, codebase understanding): Llama 4 Maverick wins convincingly. An 8x context advantage isn't something you can engineer around with clever chunking. If you need to process long inputs, the choice is obvious.
For general-purpose applications (chatbots, content generation, customer support): Llama 4 Maverick has a slight edge thanks to lower per-token inference costs and a more mature deployment ecosystem. But DeepSeek V3 is competitive on output quality.
For budget-conscious teams: Both are free to download, but Llama 4 Maverick's lower active parameter count translates to cheaper inference at scale. If your cloud bill keeps you up at night, Maverick's efficiency helps.
The open source LLM space is moving fast. Both DeepSeek and Meta are iterating aggressively, and today's best choice might shift with the next release. The good news? Since both are open weight, switching costs stay low. Pick the one that fits your current use case, ship your product, and reassess when the next generation arrives.
Can I run DeepSeek R1 or Llama 4 Maverick on a single GPU?
Neither model fits on a single consumer GPU at full precision. DeepSeek V3/R1 has 671B total parameters, requiring hundreds of gigabytes of VRAM even with INT4 quantization. Llama 4 Maverick at ~400B is lighter but still needs a multi-GPU setup. For single-GPU inference, look at smaller distilled variants or aggressive community quantizations that trade some accuracy for accessibility.
Is DeepSeek R1 safe for commercial use?
DeepSeek R1 uses the MIT license for both code and model weights, allowing unrestricted commercial use with no user-count limits. DeepSeek V3's code is MIT-licensed, but the model weights are under a custom DeepSeek License Agreement. Llama 4's community license includes a threshold restriction set at 700 million monthly active users. For most businesses, both DeepSeek and Llama licenses work fine, but review the specific terms for your deployment scale.
How does DeepSeek R1 compare to OpenAI o1 and o3?
DeepSeek R1 uses a similar chain-of-thought reasoning approach but is open weight and free to self-host. On MATH-500, R1 scores 97.3% (self-reported), competitive with o1's 94.8% on MATH. On GPQA Diamond, R1 hits 71.5% versus o1's 78% and o3's 87.7% (all self-reported by respective creators). R1 leads on math benchmarks but trails OpenAI's reasoning models on the hardest science benchmarks, with the tradeoff being zero API cost when self-hosted.
Does Llama 4 Maverick actually use its full 1M context window effectively?
Long-context models including Llama 4 can experience reduced recall accuracy for information placed in the middle of very long prompts, a known issue called 'lost in the middle.' Meta has made architectural improvements to mitigate this in Llama 4, but real-world performance varies by task. For critical retrieval over very long documents, combining the large context window with RAG techniques typically produces the best results.
Which model has better fine-tuning support?
Llama 4 currently has a stronger fine-tuning ecosystem with more tooling support, tutorials, and community-contributed LoRA adapters available on HuggingFace. DeepSeek models can be fine-tuned using standard methods like QLoRA, but fewer ready-made resources and guides exist. If you need to fine-tune quickly with minimal setup, Llama 4's mature ecosystem gives it a practical head start.