LLM Benchmarks 2026: 8 Tests and Still No Winner | AI Bytes
0% read
LLM Benchmarks 2026: 8 Tests and Still No Winner
Benchmarks
LLM Benchmarks 2026: 8 Tests and Still No Winner
We compared Claude Opus 4.6, GPT-4o, o3, DeepSeek R1, and Gemini 2.5 Pro across 8 major benchmarks. The result? No single model dominates everything — and that matters more than you think.
April 4, 2026
8 min read
404 views
Updated July 5, 2026
Claude Opus 4.6 reportedly scored 93.7% on HumanEval — among the highest code generation benchmark results posted publicly. And yet, OpenAI's o3 hit 96.7% on MATH. No single model dominates everything in 2026.
We pulled data from the top LLM benchmarks 2026 has to offer — 8 major tests — to give you the real picture of where each model excels, where it falls short, and which one actually matters for your use case. This isn't vibes-based ranking. It's numbers.
Which LLM Performs Best in 2026 Benchmarks?
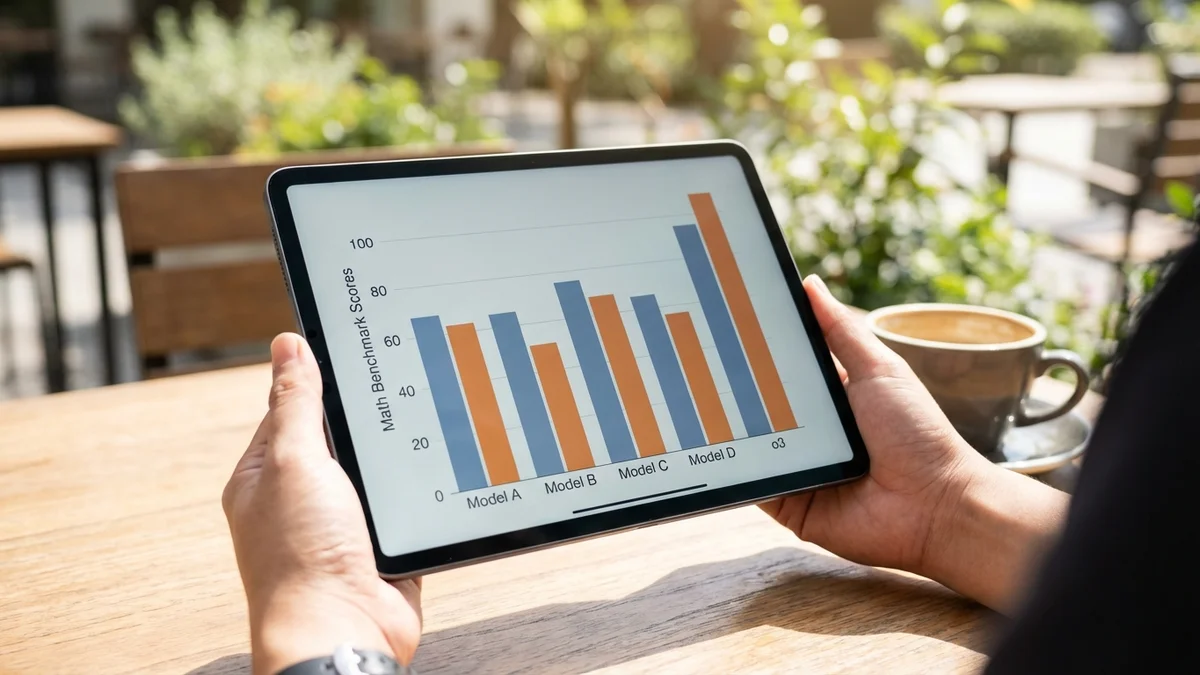
Interesting wrinkle: as of April 4, 2026, Claude Opus 4.6 leads the most benchmarks among general-purpose models, winning MMLU (92.3%), HumanEval (93.7%), and SWE-bench Verified (72%). OpenAI's o3 reasoning model dominates abstract reasoning tasks, taking first place on GPQA Diamond (87.7%), GSM8K (99.2%), and ARC-AGI (87.5%), while DeepSeek R1 edges ahead on MATH-500 (97.3% vs o3's 96.7%). All scores are self-reported by model creators. Claude Opus 4.6 and GPT-4o are among the top performers on the LMSYS Chatbot Arena, with rankings shifting frequently as new models are released.
Here's the quick overview before we dig in:
Benchmark
Winner
Score
Runner-up
Score
MMLU
Claude Opus 4.6
92.3% (self-reported)
DeepSeek R1
90.8%
HumanEval
Claude Opus 4.6
93.7% (self-reported)
GPT-4o
90.2% (self-reported)
MATH
o3
96.7%
o1
94.8%
GPQA Diamond
o3
87.7%
o1
78%
SWE-bench Verified
Claude Opus 4.6 + Scaffold
72%
o3 + Scaffold
69.1%
LMSYS Chatbot Arena
Claude Opus 4.6
Top-ranked
GPT-4o
Top-ranked
GSM8K
o3
99.2%
Claude Opus 4.6
97.8%
ARC-AGI
o3 (high compute)
87.5%
o3-mini
77%
Two things jump out immediately. First, there's no single winner. Second, the gap between "best" and "second best" is often razor-thin.
Important note: Most benchmark scores in this article are self-reported by the model creators. Independent verification of these numbers is limited, and evaluation methodologies vary between organizations.
How We Measured: The 8 Benchmarks
Not all benchmarks are created equal, and understanding what each one measures matters more than the raw numbers. Here's what we're working with:
MMLU — Massive Multitask Language Understanding. 57 subjects from elementary math to professional law. The closest thing we've to a general knowledge IQ test for LLMs.
HumanEval — Code generation. Models write Python functions from docstrings. Simple but revealing.
MATH — Competition-level mathematics. Think AMC and AIME problems, not basic arithmetic.
GPQA Diamond — Graduate-level science questions written by domain experts. Intentionally hard enough that non-experts score below 35%.
SWE-bench Verified — Real GitHub issues from popular repos. Models must write actual patches that pass tests. The most practical coding benchmark by a mile.
LMSYS Chatbot Arena — Crowd-sourced blind comparisons where real users pick which model gave the better response.
GSM8K — Grade school math word problems. Nearly saturated at this point, but still a useful floor check.
ARC-AGI — Abstract pattern reasoning designed to test genuine generalization, not memorization.
Benchmarks measure what models can do in controlled settings. What they actually do in your workflow is a different conversation entirely.
Coding: Claude Opus 4.6 Pulls Away
If you write code for a living (or want an AI that does), the coding benchmarks tell a pretty clear story.
Model
HumanEval
SWE-bench Verified
Claude Opus 4.6
93.7%
72% (w/ Scaffold)
GPT-4o
90.2%
N/A
DeepSeek V3
65.2% (self-reported, base model)
N/A
Gemini 2.5 Pro
N/A
N/A
Claude Sonnet 4.6
88%
55.3%
o3
N/A
69.1% (w/ Scaffold)
GPT-4.1
N/A
54.6%
DeepSeek R1
N/A
49.2%
Claude Opus 4.6 reportedly leads HumanEval by 3.5 percentage points over GPT-4o (self-reported scores). Note that HumanEval scores vary significantly depending on evaluation methodology (base vs. chat model, prompt format, sampling strategy).
But SWE-bench is where it gets really interesting. Solving real GitHub issues requires understanding existing codebases, writing multi-file patches, and dealing with messy real-world code. Claude Opus 4.6 with scaffolding hits 72%, beating o3's 69.1%. And the drop-off after that's steep — Claude Sonnet 4.6 at 55.3% and GPT-4.1 at 54.6% are nearly 17 points behind the leader.
So if your primary use case is coding, Claude Opus 4.6 is the clear front-runner as of April 2026. If you want to try it yourself, our Claude Code terminal AI tutorial walks you through the setup.
Math and Reasoning: o3 and DeepSeek R1 Lead the Pack
The math benchmarks paint a completely different picture. OpenAI's o3 reasoning model is among the top performers, alongside DeepSeek R1.
Model
MATH
GPQA Diamond
GSM8K
o3
96.7%
87.7%
99.2%
o1
94.8%
78%
N/A
Claude Opus 4.6
85.1%
74.9%
97.8%
Gemini 2.5 Pro
N/A
N/A
N/A
DeepSeek R1
97.3% (MATH-500)
71.5%
N/A
GPT-4o
N/A
N/A
95.8%
The gap between reasoning models (o3 at 96.7%, DeepSeek R1 at 97.3% on MATH-500) and standard models (Claude Opus 4.6 at 85.1%) is enormous — over 11 points. On GPQA Diamond (arguably the hardest benchmark on this list), o3 scores 87.7% compared to Claude Opus 4.6's 74.9%, a gap of nearly 13 points. Both o3 and R1 scores are self-reported by their respective creators.
But here's the catch: o3 is a reasoning model. It uses chain-of-thought processing that takes significantly more compute and time per query. Comparing it directly to standard models is a bit like comparing a Formula 1 car to a daily driver. Both get you there, but the cost (and impracticality for everyday trips) couldn't be more different.
o3 and DeepSeek R1 lead mathematical reasoning (both self-reported), but you're paying for that edge in latency and compute. For most users, Claude Opus 4.6's 85%+ on MATH is more than enough.
GSM8K is basically solved at this point. When your top models score between 95.8% and 99.2% on grade school math, the benchmark has served its purpose.
General Knowledge and Human Preference
MMLU and the LMSYS Chatbot Arena measure different kinds of "smart" — raw knowledge versus how people actually experience talking to a model.
Model
MMLU
LMSYS Arena Rank
Claude Opus 4.6
92.3% (self-reported)
#2
Gemini 2.5 Pro
N/A
N/A
DeepSeek R1
90.8%
N/A
Claude Sonnet 4.6
89.5% (self-reported)
#18
GPT-4o
88.7% (self-reported)
Top-ranked
Grok 3
N/A
N/A
Claude Opus 4.6 takes MMLU with 92.3% (self-reported), while both Claude Opus 4.6 and GPT-4o rank among the top models on the Chatbot Arena leaderboard. The Elo differences between top models are typically small — in practice, you'd struggle to consistently tell them apart in blind testing.
What's kind of fascinating is that MMLU rankings and Chatbot Arena rankings don't correlate perfectly. GPT-4o scores lower on MMLU among these models but has historically been a top Arena performer. This tells you that people value things beyond raw knowledge — response style, formatting, helpfulness, and personality all factor in.
The ARC-AGI Wild Card
ARC-AGI deserves its own section because the results are wild.
Model
ARC-AGI Score
o3 (high compute)
87.5%
o3-mini
77%
Claude Opus 4.6
53%
DeepSeek R1
42%
Gemini 2.5 Pro
N/A
o3 crushes this benchmark at 87.5% with high compute. The drop to Claude Opus 4.6 at 53% is massive — 34.5 points. Gemini 2.5 Pro has not published a comparable ARC-AGI score, and most non-reasoning models score well below the o3 level, suggesting this kind of abstract pattern reasoning is still genuinely hard for most architectures.
ARC-AGI is designed to resist memorization and test actual generalization ability. The fact that o3 needed "high compute" mode to hit 87.5% (while o3-mini managed 77% at lower cost) suggests brute-force reasoning time scales better here than architectural improvements alone.
The Notable Absences
A few missing players deserve mention. As of April 2026, Meta's Llama 4 Scout (with its impressive 10 million token context window) hasn't appeared in enough public benchmarks across these specific tests for a fair comparison. Same story for Mistral Large 2.5.
And despite the buzz, OpenAI hasn't released a model called GPT-5 yet. Their current lineup is GPT-4o for general use and the o-series (o1, o3) for reasoning-heavy tasks.
What These Numbers Actually Mean for You
Here's the practical breakdown by use case:
For coding: Claude Opus 4.6 is your best option. It leads both HumanEval and SWE-bench Verified by meaningful margins. As of April 2026, Anthropic prices Opus 4.6 at $5/$25 per million tokens (input/output).
For math and science: If you're working on competition-level math or graduate-level science reasoning, o3 is worth the extra cost. The 11+ point lead on MATH over the next best non-reasoning model isn't close.
For everyday chat and general tasks: GPT-4o, Claude Opus 4.6, and Gemini 2.5 Pro all rank among the top models on the Chatbot Arena leaderboard. (For a deeper head-to-head, see our Gemini vs ChatGPT benchmark comparison.) Pick based on ecosystem, pricing, and personal preference rather than benchmarks.
For long-context work: Gemini 2.5 Pro's 1 million token context window is the largest among commercial API models (Claude Opus 4.6 offers 200K tokens). If you're processing entire codebases or book-length documents, the context window matters more than a few percentage points on MMLU.
The best model in 2026 is the one that matches your actual workload — not the one with the highest number on a benchmark you'll never touch.
The Bottom Line
The 2026 LLM benchmarks picture is messier than anyone's marketing department wants you to believe. Claude Opus 4.6 leads the most benchmarks among standard models (MMLU, HumanEval, SWE-bench Verified), o3 dominates abstract reasoning (GPQA Diamond, GSM8K, ARC-AGI), and DeepSeek R1 is a strong contender on MATH. Chatbot Arena rankings shift frequently among the top models. Most scores cited here are self-reported by model creators. Gemini 2.5 Pro is a strong contender, though many of its benchmark scores across these specific tests have not been independently published.
There's no single "best AI model." There are best models for specific jobs. And honestly? That's a healthier outcome than one model ruling everything. Competition is pushing all of these scores up, quarter after quarter.
Pick the model that matches your work. Ignore the hype. Read the benchmarks. And if you're deciding how to customize a model for your workflow, our RAG vs fine-tuning comparison breaks down that decision too.
How much does Claude Opus 4.6 cost compared to GPT-4o?
As of April 2026, Claude Opus 4.6 is priced at $5 per million input tokens and $25 per million output tokens. GPT-4o costs $2.50 per million input tokens and $10 per million output tokens. So GPT-4o is roughly half the price, but Claude Opus 4.6 leads on most coding and knowledge benchmarks (self-reported). Gemini 2.5 Pro is priced at $1.25 per million input tokens and $10.00 per million output tokens (for prompts under 200K tokens), making it the most affordable frontier model.
Is o3 worth the extra cost over Claude Opus 4.6?
It depends entirely on your workload. o3 outperforms Claude Opus 4.6 by 11+ points on MATH and nearly 13 points on GPQA Diamond, making it the clear choice for advanced math and scientific reasoning. However, o3 uses chain-of-thought processing that is slower and more expensive per query. For coding, general knowledge, and everyday tasks, Claude Opus 4.6 offers better performance at lower latency.
Which AI model has the largest context window in 2026?
Among commercial API models, Gemini 2.5 Pro offers a 1 million token context window — roughly 8 times larger than GPT-4o's 128,000 tokens. Claude Opus 4.6 supports a 200,000 token context window. Meta's Llama 4 Scout claims an industry-leading 10 million token context window for open-weight models. If you need to process very long documents, full codebases, or book-length text in a single prompt, Gemini 2.5 Pro and Llama 4 Scout can handle it without chunking.
Does Llama 4 Maverick compete with Claude Opus 4.6 and GPT-4o on benchmarks?
As of April 2026, Llama 4 Maverick doesn't have published results on most of the major benchmarks covered here (MMLU, HumanEval, SWE-bench, etc.). Meta has released Maverick as a 17 billion active parameter model with 128 experts. Note that it is Llama 4 Scout (not Maverick) that features the large context window of up to 10 million tokens. Being open-weight, both models are likely to show up on independent leaderboards soon, and their open-source nature means you can run them without API costs if you have the hardware.
Can LLM benchmarks predict real-world performance?
Partially. Benchmarks like SWE-bench Verified (real GitHub issues) and LMSYS Chatbot Arena (real user preferences) correlate well with practical performance. But synthetic benchmarks like MMLU and GSM8K test narrow capabilities under controlled conditions. A model scoring 2% higher on MMLU won't feel noticeably smarter in daily use. The best approach is to test models on tasks similar to your actual workflow rather than relying solely on leaderboard rankings.