Build a RAG Chatbot With Claude and Pinecone in 30 Min | AI Bytes
0% read
Build a RAG Chatbot With Claude and Pinecone in 30 Min
Tutorials
Build a RAG Chatbot With Claude and Pinecone in 30 Min
Build a working RAG chatbot using Claude's API and Pinecone vector database in about 150 lines of Python. Step-by-step tutorial from document ingestion to grounded answers, with production tips.
April 22, 2026
13 min read
290 views
Updated July 19, 2026
Most chatbot tutorials skip the hard part. They show you how to call an API, slap a text box on a web page, and call it a day. But a chatbot that can only answer from its training data is practically useless for anything business-critical. You need your bot to know your data.
That's what retrieval-augmented generation (RAG) solves. A RAG chatbot pulls relevant documents from a vector database and feeds them to the LLM as context, instead of relying solely on baked-in knowledge. The result is a chatbot that answers questions about your specific data with real accuracy, not hallucinated guesses.
In this tutorial, you'll build a RAG chatbot using Claude's API for generation and Pinecone as your vector store. About 150 lines of Python. About 30 minutes of your time.
What You'll Build
By the end of this tutorial, you'll have a working Python chatbot that:
Ingests your documents (text files, markdown, or any plain text)
Converts them into vector embeddings and stores them in Pinecone
Retrieves relevant chunks when a user asks a question
Sends that context to Claude to generate grounded, accurate answers
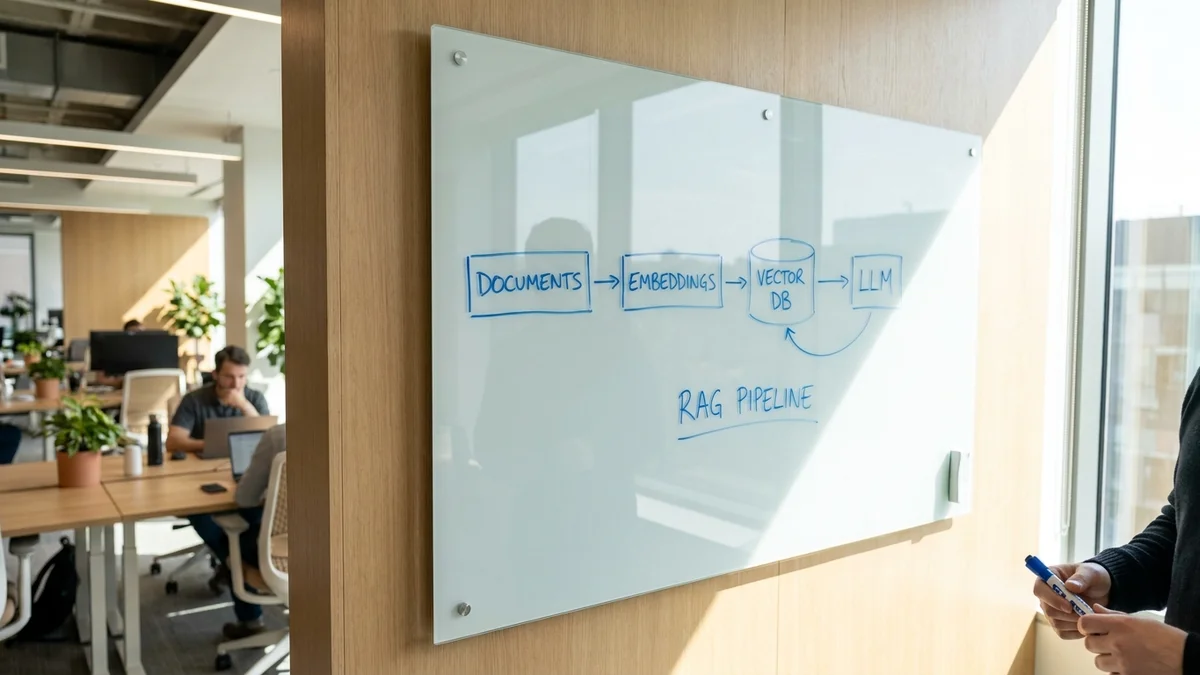
The architecture is dead simple: documents go in, vectors get stored, questions trigger retrieval, Claude generates answers. No frameworks, no unnecessary abstractions.
import os
from dotenv import load_dotenv
load_dotenv()
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
Step 2: Initialize Pinecone
Pinecone's serverless indexes are the fastest way to get a RAG chatbot running. No infrastructure to provision, no capacity planning.
Python
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key=PINECONE_API_KEY)
index_name = "rag-chatbot"
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=384,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
index = pc.Index(index_name)
The dimension=384 matches the output size of all-MiniLM-L6-v2, the embedding model we'll use next. If you switch embedding models later, update this value to match.
Step 3: Chunk, Embed, and Store Your Documents
This is where your data enters the pipeline. You'll split documents into smaller pieces, generate vector embeddings for each piece, and upload everything to Pinecone.
Python
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer("all-MiniLM-L6-v2")
def chunk_text(text, chunk_size=500, overlap=50):
"""Split text into overlapping chunks."""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start = end - overlap
return chunks
def ingest_document(filepath, index):
"""Read, chunk, embed, and store a document."""
with open(filepath, "r", encoding="utf-8") as f:
text = f.read()
chunks = chunk_text(text)
embeddings = embed_model.encode(chunks)
vectors = []
for i, (chunk, embedding) in enumerate(zip(chunks, embeddings)):
vectors.append({
"id": f"{filepath}-chunk-{i}",
"values": embedding.tolist(),
"metadata": {
"text": chunk,
"source": filepath,
"chunk_index": i
}
})
# Upsert in batches of 100
for i in range(0, len(vectors), 100):
index.upsert(vectors=vectors[i:i+100])
print(f"Ingested {len(chunks)} chunks from {filepath}")
A chunk_size of 500 characters with 50-character overlap is a solid starting point. Larger chunks preserve more surrounding context but reduce retrieval precision. Smaller chunks are sharper but might miss important details. And honestly, getting this balance right is more art than science.
Step 4: Build the Retrieval Function
When a user asks a question, you need to find the most relevant chunks from your vector database. This is the "retrieval" half of RAG.
Python
def retrieve_context(query, index, top_k=5):
"""Find the most relevant document chunks for a query."""
query_embedding = embed_model.encode(query).tolist()
results = index.query(
vector=query_embedding,
top_k=top_k,
include_metadata=True
)
contexts = []
for match in results["matches"]:
contexts.append({
"text": match["metadata"]["text"],
"source": match["metadata"]["source"],
"score": match["score"]
})
return contexts
Setting top_k=5 returns the five most similar chunks. You can increase this to give Claude more material to work with, but you'll burn through tokens faster and pay more per request. For most use cases, 3 to 7 chunks hits the sweet spot.
Step 5: Connect Claude for Answer Generation
Now for the best part. You'll send the retrieved context to Claude along with the user's question. The system prompt is critical; it tells Claude to stick to the provided context and not make things up.
Python
import anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def generate_answer(query, contexts):
"""Send retrieved context and query to Claude."""
context_text = "\n\n---\n\n".join(
f"[Source: {c['source']}]\n{c['text']}"
for c in contexts
)
system_prompt = (
"You are a helpful assistant that answers questions "
"based only on the provided context. "
"If the context doesn't contain the answer, say so clearly. "
"Cite which source document your answer comes from. "
"Be concise and direct."
)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=system_prompt,
messages=[
{
"role": "user",
"content": f"Context documents:\n\n{context_text}\n\nQuestion: {query}\n\nAnswer based on the context above:"
}
]
)
return message.content[0].text
We're using Claude Sonnet 4.6 instead of Opus. For RAG applications, Sonnet is clearly the better choice. It delivers excellent quality for context-grounded responses at $3 per million input tokens (compared to $5 for Opus). Since your chatbot sends retrieved context with every single query, those per-token costs compound quickly. Claude's 1M-token context window also means you have plenty of room to include large amounts of retrieved text without truncation.
Step 6: Wire It All Together
Combine everything into a working chat loop:
Python
import glob
def chat():
"""Run the RAG chatbot."""
for filepath in glob.glob("documents/*.txt"):
ingest_document(filepath, index)
print("RAG Chatbot ready! Type 'quit' to exit.\n")
while True:
query = input("You: ").strip()
if query.lower() == "quit":
break
contexts = retrieve_context(query, index)
if not contexts or contexts[0]["score"] < 0.3:
print("Bot: I couldn't find relevant information in the documents.\n")
continue
answer = generate_answer(query, contexts)
print(f"Bot: {answer}\n")
if __name__ == "__main__":
chat()
The score < 0.3 threshold filters out weak matches. Cosine similarity below 0.3 usually means Pinecone didn't find anything meaningful. Adjust this based on your data, but 0.3 is a reasonable default.
Tips and Common Pitfalls
A RAG chatbot that can only search its training data is practically useless for anything business-critical. Ground it in your actual data, and it becomes genuinely useful.
Chunk size matters more than you think. If your answers are vague or incomplete, try bumping chunk size to 800-1000 characters. If you're pulling in irrelevant noise, drop it to 300-400. So start with 500 and tune from there.
Don't skip the overlap. Chunks without overlap create hard splits that break sentences and lose context. Even 50 characters of overlap makes a noticeable difference in retrieval quality, and the storage cost is negligible.
Pick the right embedding model.all-MiniLM-L6-v2 is fast and free but has limited input length. For longer chunks, switch to all-mpnet-base-v2 (which outputs 768-dimensional vectors, so update your Pinecone index dimension accordingly).
Cache frequent queries. If your chatbot answers the same questions repeatedly, cache both the Pinecone results and Claude responses. A simple dictionary cache or Redis layer saves real money at scale.
Add retry logic for production. Both the Anthropic API and Pinecone have rate limits. Add exponential backoff for anything customer-facing:
Python
import time
def retry_with_backoff(func, max_retries=3):
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt)
Testing Your Chatbot
Drop a few text files into your documents/ folder and run python chatbot.py. Start with questions you know the documents can answer, then push the boundaries:
Questions that require combining info from multiple documents
Questions the documents don't cover at all (the bot should admit it)
Vague or ambiguous questions
Follow-up questions that assume prior context
Check the similarity scores coming back from Pinecone. Scores above 0.7 indicate strong matches. Between 0.4 and 0.7, review the results manually. Below 0.4, the retrieval probably missed. But don't obsess over individual scores; focus on whether the final answers are actually useful to your users.
Next Steps
Once your basic RAG chatbot is working, consider these improvements:
Conversation memory: Store previous messages and include them in the prompt so Claude can handle follow-ups naturally
PDF and Word support: Use pypdf for PDFs or python-docx for Word documents
Web interface: A quick FastAPI backend with a simple frontend turns your CLI tool into something shareable
Hybrid search: Combine vector similarity with BM25 keyword matching for better retrieval, especially on technical documents
Metadata filtering: Tag documents by category, date, or source and filter at query time for more precise results
So that's your RAG chatbot with Claude and Pinecone. About 150 lines of Python, two API keys, and you've got a system that can answer questions grounded in your actual data. Not bad for 30 minutes of work.
Can I use OpenAI embeddings instead of sentence-transformers for my RAG chatbot?
Yes. OpenAI's text-embedding-3-small outputs 1536-dimensional vectors and handles longer text inputs than all-MiniLM-L6-v2. You'd need to set your Pinecone index dimension to 1536 and swap the encode call for an OpenAI API request. The tradeoff is cost: OpenAI charges per token for embeddings, while sentence-transformers runs locally for free. For production apps with heavy ingestion, the API costs can add up.
How much does it cost to run a RAG chatbot with Claude and Pinecone monthly?
For a low-traffic chatbot handling around 1,000 queries per day with 5 retrieved chunks each, expect roughly $5-15/month in Claude Sonnet 4.6 API costs (at $3 per million input tokens). Pinecone's free Starter plan includes up to 2 GB of storage and up to 5 serverless indexes with no monthly charge, which is enough for small to medium document collections. The local embedding model (sentence-transformers) costs nothing. Your main cost driver will be Claude API usage at scale.
Can I just paste all my documents into Claude's context window instead of using a vector database?
You can, and for small document sets (under 50 pages) it actually works well. The problem is scale and cost. Claude Sonnet 4.6's 1M-token context window holds roughly 750K words, which sounds like a lot until you're dealing with hundreds of documents. Every query would send your entire corpus, costing far more per request. RAG lets you send only the 3-7 most relevant chunks, keeping costs low and answers focused. Use the full context window for small, static datasets; use RAG for anything that grows.
How do I update or delete documents in a Pinecone RAG chatbot after deployment?
To update a document, delete its old vectors and re-ingest the new version. Pinecone supports deletion by ID or by metadata filter. Since the tutorial uses IDs like 'filepath-chunk-0', you can delete all vectors matching a file with index.delete(filter={"source": {"$eq": "documents/old-file.txt"}}). Then re-run ingest_document with the updated file. For large-scale updates, consider adding a version timestamp to your metadata so you can query only the latest version.
What's the best chunk size for RAG with Claude and Pinecone?
There's no universal best, but 400-800 characters works well for most text documents. Technical docs with dense information benefit from smaller chunks (300-500 chars) for precision, while narrative content like reports or articles works better with larger chunks (600-1000 chars) that preserve context. Always use 10-20% overlap between chunks. Test with your actual data by running 20-30 representative queries and checking whether the retrieved chunks contain the right answers.