Tutorials
Build a Multi-Agent AI System From Scratch in 2026
A practical Python tutorial for building a multi-agent AI system from scratch. No frameworks, no magic, just an orchestrator, workers, and clean message passing.
May 16, 2026
A practical Python tutorial for building a multi-agent AI system from scratch. No frameworks, no magic, just an orchestrator, workers, and clean message passing.

Most multi-agent tutorials hand you a bloated framework, a 40-line config file, and call it a day. That's not learning. That's copy-paste.
So this guide goes the other way. You'll build a multi-agent AI system from scratch in Python, using nothing but the Anthropic SDK and the standard library. By the end you'll have an orchestrator that breaks down a task, dispatches it to specialist agents, and merges their outputs into a final answer. The whole thing fits in under 200 lines.
And yes, it actually works.
You'll build a research assistant with three agents working together:
This is the classic orchestrator-worker pattern, and it's the foundation underneath production systems like Anthropic's research agent and most agentic RAG setups. Once you understand it, every other multi-agent framework (CrewAI, AutoGen, LangGraph) becomes much easier to read.
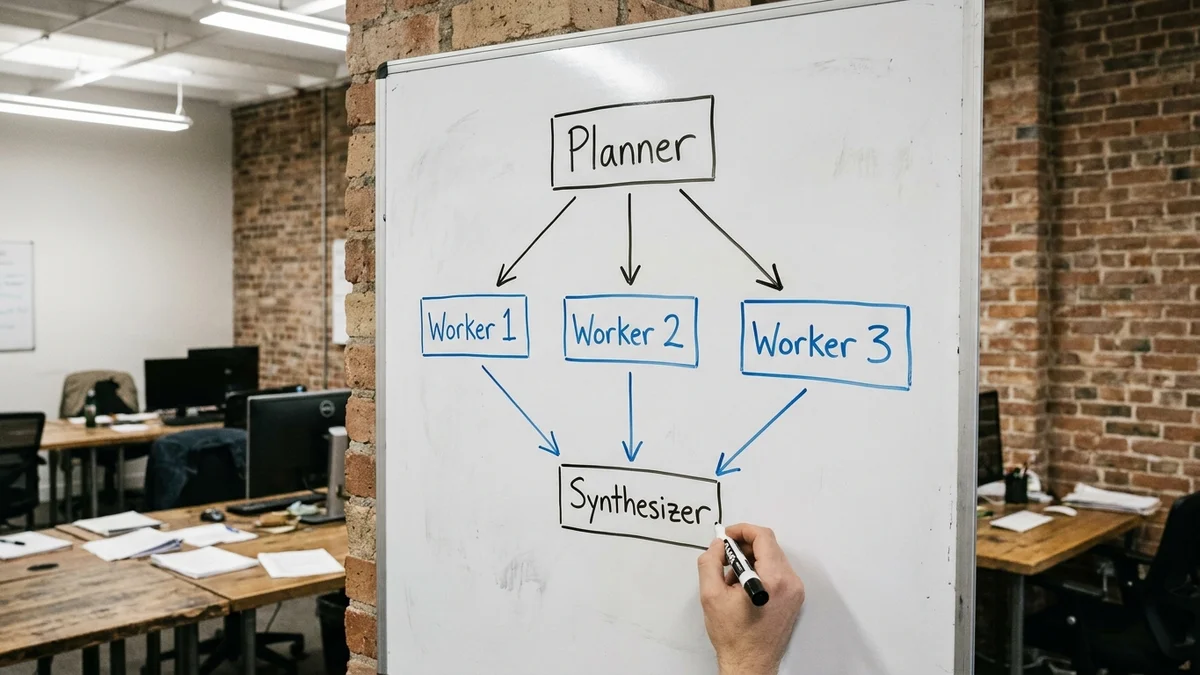
We'll use Claude Sonnet 4.6 for the workers (fast, cheap at $3/$15 per million tokens) and Claude Opus 4.7 for the planner and synthesizer where reasoning matters more. You can swap in GPT-4o or DeepSeek with about ten lines of changes.
Before you start:
async/await (we'll run workers in parallel)Install the SDK:
pip install anthropic
Set your key:
export ANTHROPIC_API_KEY="sk-ant-..."
That's the whole setup. No vector database, no framework, no Docker. Pretty refreshing, not gonna lie.
Every agent in your system needs the same three things: a system prompt, an input, and a structured output. So let's build a single Agent class that all three roles will reuse.
import os
import json
import asyncio
from anthropic import AsyncAnthropic
client = AsyncAnthropic()
class Agent:
def __init__(self, name: str, model: str, system: str):
self.name = name
self.model = model
self.system = system
async def run(self, user_message: str) -> str:
response = await client.messages.create(
model=self.model,
max_tokens=2048,
system=self.system,
messages=[{"role": "user", "content": user_message}],
)
return response.content[0].text
That's the entire abstraction. One class. One method. If you're used to LangChain's Runnable chains, this might feel suspiciously simple. But that's the point. Most of the complexity in agent frameworks exists to support features you don't need yet.
The planner is the brain of the operation. It receives the user's question and produces a JSON list of subtasks. We want strict structure here, so the system prompt does a lot of work.
PLANNER_SYSTEM = """You are a planning agent. Given a user question, break it
into 2-4 independent research subtasks that can be answered in parallel.
Return ONLY valid JSON in this exact format:
{"subtasks": ["task 1", "task 2", "task 3"]}
Rules:
- Each subtask must be answerable on its own
- Subtasks must not depend on each other's output
- Phrase each subtask as a specific question
"""
planner = Agent(
name="planner",
model="claude-opus-4-7",
system=PLANNER_SYSTEM,
)
async def plan(question: str) -> list[str]:
raw = await planner.run(question)
return json.loads(raw)["subtasks"]

A word of caution: JSON parsing from LLMs is fragile. In production you'd want either tool use (the structured output feature in the Anthropic API) or a retry loop that catches json.JSONDecodeError. For learning purposes, this is fine.
If subtask 2 depends on subtask 1's output, you can't parallelize them. The whole speed advantage of multi-agent systems comes from running workers concurrently. So the planner's job is partly to enforce independence by phrasing tasks that don't reference each other.
This is the single biggest mistake beginners make. They write a planner that produces sequential steps ("first find X, then use X to find Y"), and end up with a slow agent that's just doing chain-of-thought through three API calls. Don't do that.
Workers are the simplest piece. Each one gets a subtask, does the research, returns a short factual answer. We'll use Claude Sonnet 4.6 because it's fast and the work doesn't need deep reasoning.
WORKER_SYSTEM = """You are a research worker. Answer the given question
concisely and factually. If you don't know, say so. Maximum 200 words.
Cite sources only if you are certain they exist."""
worker = Agent(
name="worker",
model="claude-sonnet-4-6",
system=WORKER_SYSTEM,
)
async def do_subtask(subtask: str) -> dict:
answer = await worker.run(subtask)
return {"subtask": subtask, "answer": answer}

Notice we return a dict, not a raw string. The synthesizer needs to know which subtask each answer corresponds to. This sounds obvious but I've seen plenty of broken implementations where workers just dump strings into a list and the final agent gets confused about what answered what.
The synthesizer takes the planner's subtasks and the workers' answers, then writes the final response. It's the only agent that sees the original question alongside all the partial results.
SYNTHESIZER_SYSTEM = """You are a synthesis agent. You receive a user's
original question and a set of subtask answers from research workers.
Write a single, coherent answer to the original question that integrates
the worker findings. Do not mention the multi-agent process. Do not list
the subtasks. Write as if you researched everything yourself."""
synthesizer = Agent(
name="synthesizer",
model="claude-opus-4-7",
system=SYNTHESIZER_SYSTEM,
)
async def synthesize(question: str, results: list[dict]) -> str:
payload = f"Original question: {question}\n\nWorker results:\n"
for r in results:
payload += f"\nQ: {r['subtask']}\nA: {r['answer']}\n"
return await synthesizer.run(payload)
That instruction about "don't mention the multi-agent process" matters more than you'd think. Without it, the synthesizer often writes things like "Based on the research from my workers..." which makes the output sound like a project status report instead of an answer.
Now the fun part. The orchestrator runs the planner, fans out to workers in parallel using asyncio.gather, then calls the synthesizer.
async def orchestrate(question: str) -> str:
print(f"[orchestrator] Planning subtasks...")
subtasks = await plan(question)
print(f"[orchestrator] Got {len(subtasks)} subtasks")
print(f"[orchestrator] Running workers in parallel...")
results = await asyncio.gather(*[do_subtask(s) for s in subtasks])
print(f"[orchestrator] Synthesizing final answer...")
return await synthesize(question, results)
if __name__ == "__main__":
question = "Compare Claude Opus 4.7, GPT-4o, and Gemini 2.5 Pro on coding benchmarks and pricing."
final = asyncio.run(orchestrate(question))
print("\n=== FINAL ANSWER ===\n")
print(final)
Run it:
python agents.py
For the sample question above, you'll see roughly: the planner generates three subtasks (coding benchmarks, pricing, context windows), the three workers fire off concurrently in about 3-5 seconds total instead of 9-15 sequentially, and the synthesizer produces a clean comparison. End-to-end token spend lands around 8,000-12,000 input tokens and 1,500-2,500 output tokens, or roughly $0.06-$0.12 per query with the model mix above. That parallelism is the entire reason this pattern exists.
A few things will bite you the first time you build this.
The planner produces dependent subtasks. Already covered, but worth repeating because it kills your performance gains. If you see workers waiting on each other, your planner prompt needs more aggressive independence rules.
JSON parsing fails silently. When the planner returns malformed JSON, json.loads throws and your whole pipeline dies. Wrap it in a try/except with one retry. Better: use the tool use API for guaranteed structure.
Workers hallucinate citations. LLMs love inventing plausible-looking URLs. The system prompt above tells workers to cite "only if certain" but the real fix is giving workers actual tool access (web search, RAG retrieval). Without grounding, treat factual claims as suspect.
Costs explode. Three agents per query means three API calls minimum, often more. At Opus 4.7 prices ($5/$25 per million tokens as of early 2026), a single query with long context can run $0.10-$0.30. Use Sonnet for workers. Use Opus only where reasoning quality matters.
Async errors get swallowed. If one worker throws an exception inside asyncio.gather, the others might silently fail too. Add return_exceptions=True to gather, then check each result before passing to the synthesizer.
Three quick verification steps before you call it done.
Timing test: run a question with three subtasks. Total time should be roughly plan_time + max(worker_times) + synthesis_time, not the sum of all four. If it's the sum, your parallelism is broken.
Determinism test: run the same question five times. The plans should be similar but not identical. If they're wildly different each run, your planner prompt is too vague. If they're byte-identical, you might have temperature set to 0 (which is fine, but worth knowing).
Failure injection: deliberately break one worker (raise an exception inside do_subtask). The system should either recover gracefully or fail loudly with a clear error. Silent partial failures are the worst kind of bug.
For more rigorous evaluation, Anthropic's evaluation cookbook has examples of running structured eval suites against agent systems.
You've got the skeleton. The next layers, roughly in order of usefulness:
Tool use for workers. Give workers actual capabilities: web search via Exa, code execution, file reading. This is the biggest jump in real-world usefulness. A worker that can search the web is dramatically more useful than one relying on training data.
Memory between turns. Right now each query is independent. Add a simple conversation history dict keyed by session ID, and pass relevant context into the planner.
Worker specialization. Instead of identical workers, build different ones with different system prompts: a "data worker" that loves numbers, a "summary worker" that writes prose, a "code worker" that returns runnable snippets. The planner then assigns subtasks based on type.
Observability. Log every agent call with input, output, latency, and token count. When something goes wrong (and it will), you need to see which agent produced the bad output. Langfuse and Helicone both work well for this without forcing you into a framework.
Once you've added tool use and memory, you've essentially built a smaller version of what production agent systems do. From there, frameworks like LangGraph start making sense because you understand what they're abstracting over. Build from scratch first. Adopt frameworks second. That order matters.
If you're weighing whether to stay with raw asyncio or graduate to a framework, here's the honest tradeoff in concrete terms:
| Concern | Raw asyncio (this guide) | LangGraph / CrewAI | AutoGen |
|---|---|---|---|
| Lines of code for a 3-agent pipeline | ~150 | ~80-100 + framework | ~120 + framework |
| New dependencies | 1 (anthropic SDK) | 12-25 transitive | 30+ transitive |
| Time to first run | 5 minutes | 30-60 minutes (concepts + setup) | 45-90 minutes |
| Conditional routing (if/else between agents) | Manual (write the if) | Built-in graph edges | Built-in via group chat |
| Human-in-the-loop checkpoints | Roll your own | Native interrupt API | Native via UserProxyAgent |
| Debugging when something breaks | Read your own 150 lines | Trace through framework internals | Trace through framework internals |
| Lock-in risk if you swap providers | Near zero | High (graph definitions are framework-specific) | High |
The rule of thumb? Build raw until your conditional orchestration logic exceeds ~50 lines or you need persistent state across sessions. That's roughly when the framework's abstractions start paying for themselves instead of taxing you.
Sources
No. Frameworks like LangChain, CrewAI, and AutoGen add convenience but introduce learning overhead and lock you into their abstractions. For production systems handling fewer than ~10 agent types, raw SDK calls plus a small orchestrator (like the one above) are often faster to debug and cheaper to maintain. Adopt a framework once you hit features you genuinely need, such as streaming graph execution or built-in human-in-the-loop checkpoints.
Expect 2-5x the cost of a single call, depending on how many workers fire. A three-agent pipeline (planner + 3 workers + synthesizer) using Claude Opus 4.7 for orchestration and Sonnet 4.6 for workers typically lands at $0.05-$0.20 per query as of early 2026. The biggest cost lever is using cheaper models for workers, since they handle the bulk of token volume.
Yes, and it works well. Swap the Anthropic client for an OpenAI-compatible client pointing at a provider like Together AI, Fireworks, or DeepSeek's API. The architecture is identical. One caveat: open models tend to follow strict JSON formatting instructions less reliably, so you'll want a JSON-mode flag or a retry loop around the planner's output parsing.
With the basic `asyncio.gather` setup, one exception cancels the others. Add `return_exceptions=True` to gather, then inspect results before synthesis. A common pattern is to retry failed workers once with a longer timeout, then pass partial results to the synthesizer with a note about which subtasks are missing. The synthesizer can produce a useful answer from 2 out of 3 subtasks in most cases.
When your agent flow stops being a simple fan-out. If you need conditional routing ("if worker A says X, run worker D instead of B"), cyclic execution (agents that call themselves), or persistent state across long-running sessions, a graph framework pays for itself. For pure orchestrator-worker patterns, raw asyncio stays simpler indefinitely.





