Comparisons
GPT vs Claude Opus 4.6: The Honest 2026 Showdown
Claude Opus 4.6 leads SWE-bench Verified at 75.6% while GPT-4o stays the cheaper generalist. A data-backed breakdown of price, features, and real coding performance.
June 8, 2026
Claude Opus 4.6 leads SWE-bench Verified at 75.6% while GPT-4o stays the cheaper generalist. A data-backed breakdown of price, features, and real coding performance.

Picking between GPT and Claude Opus 4.6 in 2026 mostly comes down to one question: do you need the cheapest decent model, or the best one for agentic coding? That's the short answer. The longer answer involves benchmarks, pricing math, and a few surprises buried in the official numbers.
This GPT vs Claude Opus 4.6 comparison cuts through the marketing. We'll use real benchmark data from the SWE-bench Verified leaderboard, official pricing from both vendors, and the agent-coding scores that actually predict whether these models can finish a pull request without you babysitting them.
And yes, the conclusion might annoy fans of both camps.
Claude Opus 4.6 is the better model for coding, complex reasoning, and long-context analysis. GPT-4o is the better model for general chat, multimodal tasks, and projects where API cost matters more than the last few percentage points of accuracy. If you're building agents that write production code, Opus wins. If you're building a customer support bot that summarizes tickets, GPT-4o is fine and cheaper.
That's the TL;DR. The rest of this piece explains why.
A few quick notes before going deeper. Anthropic prices Opus 4.6 at $5 input / $25 output per million tokens. OpenAI's GPT-4o still sits at $2.5 input / $10 output per million tokens, the same pricing it has carried for over a year. So the cost gap is real but no longer the multi-x chasm it used to be on older Opus versions.
| Feature | Claude Opus 4.6 | GPT-4o |
|---|---|---|
| Provider | Anthropic | OpenAI |
| Context window | 200,000 tokens | 128,000 tokens |
| Input price (per MTok) | $5 | $2.50 |
| Output price (per MTok) | $25 | $10 |
| SWE-bench Verified (mini-agent, single attempt) | 75.6% | N/A (GPT-5 family: 65–72.8%) |
| Native multimodal | Vision + text | Vision + audio + text |
| Best for | Coding, reasoning, agents | General chat, voice, vision |
(MMLU, HumanEval, and Chatbot Arena Elo are no longer routinely reported by Anthropic or OpenAI for these specific models; we've left them out rather than cite stale or self-reported figures.)
GPT-4o is cheaper. Not by a small amount, by 2x on input and 2.5x on output. At $2.5 per million input tokens and $10 per million output tokens, OpenAI's pricing page makes GPT-4o one of the most economical legacy frontier models on the market.
Claude Opus 4.6 sits at $5 input and $25 output per million tokens. That's still pricier, but it's no longer the 6x gap it used to be against older Opus generations. According to Anthropic's pricing docs, prompt caching can knock 90% off cache reads, which matters a lot for long-context coding sessions where the same codebase context gets reused.
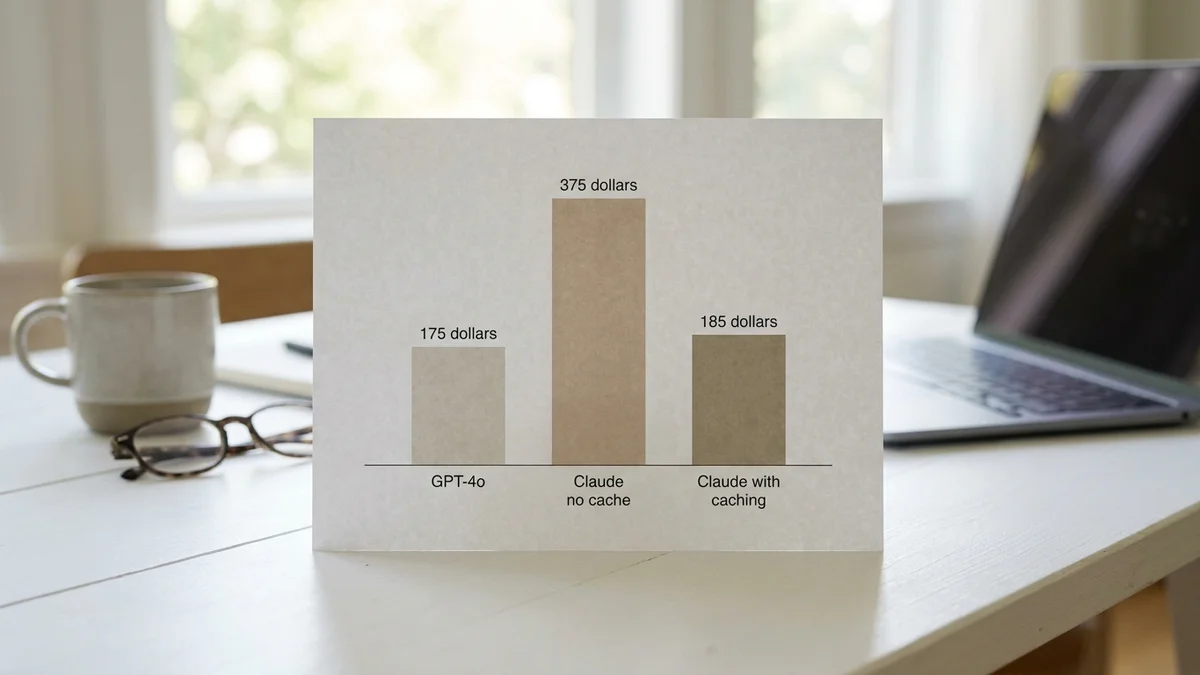
Let's do the math on a realistic workload. Say you're running a coding agent that processes 50 million input tokens and generates 5 million output tokens per month.
With prompt caching on Claude (assume 70% cache hit rate on inputs), that Opus number drops closer to $185. So in steady-state agentic workloads, the gap nearly closes. Without caching, GPT-4o stays roughly 2x cheaper.
For a chat app with low context reuse, GPT-4o wins on pure cost. For a coding agent with heavy context reuse, the difference is marginal. (If you want the cheaper Claude tier in this fight, our Claude Sonnet 4.6 vs GPT-4o trade-offs is the relevant comparison.)
It gets interesting from here. The public benchmark data tells a clear story: Claude Opus 4.6 leads on agentic coding tasks, GPT-4o stays competitive on general chat.
The most decision-relevant benchmark is SWE-bench Verified, which measures whether models can actually resolve real GitHub issues. On the official SWE-bench leaderboard (mini-swe-agent, single attempt), Claude Opus 4.6 resolves 75.6% of tasks. That puts it near the top of the leaderboard, behind Claude Opus 4.5 (high reasoning) at 76.8% and roughly tied with Gemini 3 Flash preview (75.8%).
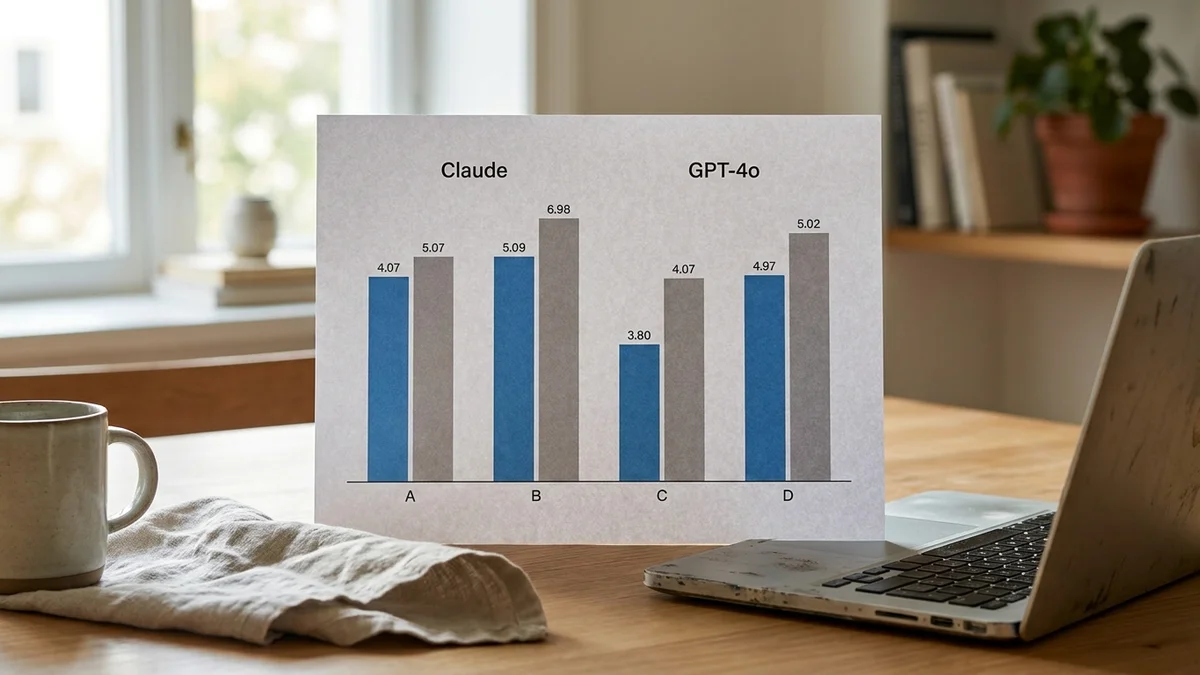
For context on OpenAI's side, GPT-5-2 Codex scores 72.8%, GPT-5.2 (high reasoning) scores 71.8%, the older GPT-5 (2025-08-07) sits at 65.0%, and o3 sits at 58.4%. GPT-4o is not a competitive entry on this leaderboard — Anthropic's CLI tool Claude Code has been eating GitHub Copilot's lunch in agentic coding workflows for exactly this reason — see our Claude Code vs Cursor vs Copilot breakdown for how the dev tooling shakes out.
If your job involves shipping code, this gap is the single most important data point in the entire comparison.
On general reasoning, no current vendor publishes head-to-head MMLU numbers for GPT-4o vs Opus 4.6 the way they used to. The newer reasoning families — OpenAI's GPT-5 series and Anthropic's higher reasoning Opus modes — now dominate the math and science leaderboards. If you specifically need PhD-level science reasoning, neither GPT-4o nor Claude Opus 4.6 is your best pick. You'd reach for a reasoning-tier model instead.
In casual use, GPT-4o still feels conversational and quick. Claude can sometimes feel overly cautious or wordy (not gonna lie, the disclaimers can grate).
For pure chat, voice mode, image understanding mixed with quick replies? GPT-4o is excellent. The model's ChatGPT integration is also more polished, especially the voice features.
Claude Opus 4.6: 200,000 tokens. GPT-4o: 128,000 tokens. That's a 56% larger context for Claude, which translates to roughly 150,000 words of input. For document analysis, codebase ingestion, and long conversations, Opus has a real edge.
Google's Gemini 3 Pro and Flash families push context windows further, so if you're processing massive corpora, Gemini is worth a look. Neither GPT-4o nor Opus 4.6 currently competes at that scale.
GPT-4o was built as a natively multimodal model. Text, images, audio in, audio out. The voice mode in particular feels closer to real-time conversation than anything Anthropic offers.

Claude Opus 4.6 handles text and vision, with strong document and chart analysis. No native audio. So if you're building a voice product, GPT-4o is the obvious pick.
Both models support function calling, but Claude's tool use documentation and its computer use API have made it the favorite for agentic workflows. The combination of high SWE-bench scores and reliable tool calling is why so many developer tools (Cursor, Cline, Aider, Claude Code itself) default to Claude.
GPT-4o's tool use works fine, but for multi-step agent loops, Claude's lower error rate compounds into significantly better outcomes.
Claude refuses more often. Sometimes appropriately, sometimes annoyingly. Anthropic's Constitutional AI approach makes Opus 4.6 cautious about edge cases that GPT-4o handles without hesitation.
For enterprise compliance teams, this is a feature. For creative writers or red-teamers, it's friction.
GPT-4o is faster end-to-end. Time-to-first-token is lower, and streaming feels snappier in practice. Claude Opus 4.6 is no slouch, but the API consistently runs slower on the same prompts. For interactive chat UIs, this matters. For batch processing, it doesn't.
Choose Claude Opus 4.6 if you're:
Choose GPT-4o if you're:
A worth-noting reality: many production teams use both. They route coding and analysis to Claude, route chat and voice to GPT-4o. The OpenRouter and LiteLLM ecosystems make this multi-model routing trivial to set up.
If you're starting a new project in mid-2026, GPT-4o is no longer OpenAI's frontier — the GPT-5 family (GPT-5, GPT-5.1, GPT-5.2, GPT-5.4, GPT-5.5, plus pro and codex variants) has taken that role and posts SWE-bench scores in the 65–72.8% range depending on variant. We've kept this comparison focused on GPT-4o because it remains the price/performance pick for high-volume chat workloads, but for a like-for-like fight against Claude Opus 4.6, GPT-5.2 or GPT-5-2 Codex are the more honest opponents on coding tasks (our GPT-5 vs Claude Opus 4.6 benchmark verdict digs into that head-to-head).
| Use Case | Winner |
|---|---|
| Coding agents | Claude Opus 4.6 |
| General chat | GPT-4o |
| Voice apps | GPT-4o |
| Long documents | Claude Opus 4.6 |
| Cost-sensitive workloads | GPT-4o |
| Complex reasoning | Claude Opus 4.6 |
| Image analysis | Tie |
| Customer support bots | GPT-4o |
| Research analysis | Claude Opus 4.6 |
Overall winner? Honestly, it depends on what you're building. But if forced to pick one model for a generalist developer in 2026, the pick is Claude Opus 4.6, with GPT-4o as the secondary model for cost-sensitive or voice-driven features.
The 2x price premium on Opus is real, but the coding accuracy gap is bigger than the cost gap when you account for the developer time saved by fewer wrong answers. And with prompt caching, the effective price gap shrinks to almost nothing on long-context workloads.
GPT-4o is the better deal. Claude Opus 4.6 is the better model for coding. Pick based on which one matters more for your project.
Sources
Yes. Anthropic's tool use API supports parallel function calls, structured outputs, and computer use. In multi-step agent loops, Claude generally has a lower tool-call error rate than GPT-4o, which is part of why frameworks like Cline and Aider default to Claude. The API syntax differs slightly but is functionally equivalent for most use cases.
You need a separate Anthropic account. Claude is available at claude.ai with Free, Pro, Max, Team, and Enterprise tiers, or through the API. Multi-model platforms like Poe and OpenRouter let you access both GPT-4o and Claude Opus 4.6 under one subscription, which is convenient if you switch between them often.
Both vendors set default rate limits based on usage tier and prepayment history. OpenAI generally exposes higher default tokens-per-minute on lower tiers, while Anthropic's limits scale aggressively once you have established billing history. For high-volume production workloads, contact sales at either company for custom tiers.
Yes, significantly. Anthropic's prompt caching offers a 90% discount on cached reads. For coding agents that reuse codebase context across many calls, real-world savings of 50-70% on input costs are common. The catch: cache writes carry a premium, so caching only pays off when you reuse the cached prefix at least a couple of times.
It already has. As of mid-2026, OpenAI has shipped GPT-5, 5.1, 5.2, 5.4, and 5.5 along with mini, nano, pro, and codex variants. On agentic coding benchmarks like SWE-bench Verified, GPT-5-2 Codex hits 72.8% and GPT-5.2 high reasoning hits 71.8%, which puts the frontier OpenAI models within striking distance of Claude Opus 4.6's 75.6%. GPT-4o remains OpenAI's price/performance pick for high-volume chat, but it is no longer their frontier coding model.