Comparisons
GPT-5 vs Claude Opus 4.6: The 2026 Benchmark Verdict
Claude Opus 4.6 wins coding. GPT-5 wins reasoning. The 2026 benchmark gaps tell a clear story, and most teams should genuinely run both.
May 4, 2026
Claude Opus 4.6 wins coding. GPT-5 wins reasoning. The 2026 benchmark gaps tell a clear story, and most teams should genuinely run both.

OpenAI shipped GPT-5. Anthropic shipped Claude Opus 4.6. And the developer community spent the last few months arguing over which one actually deserves the top spot on your API bill. So which model wins?
The short, honest answer: it depends on whether you're shipping code or solving math problems. The longer answer needs a benchmark-by-benchmark breakdown, because the headline "frontier model" framing hides a real split in capabilities.
This GPT-5 vs Claude Opus 4.6 comparison goes through the published benchmarks, the pricing math, the tooling ecosystem, and the workloads where each model genuinely earns its keep.
If you're picking between GPT-5 and Claude Opus 4.6 in 2026, the choice maps cleanly to your workload. Claude Opus 4.6 dominates real-world coding tasks, agentic workflows, and long-document analysis. GPT-5 (along with OpenAI's o-series reasoning lineage) wins on pure math, abstract reasoning, and PhD-level science questions.
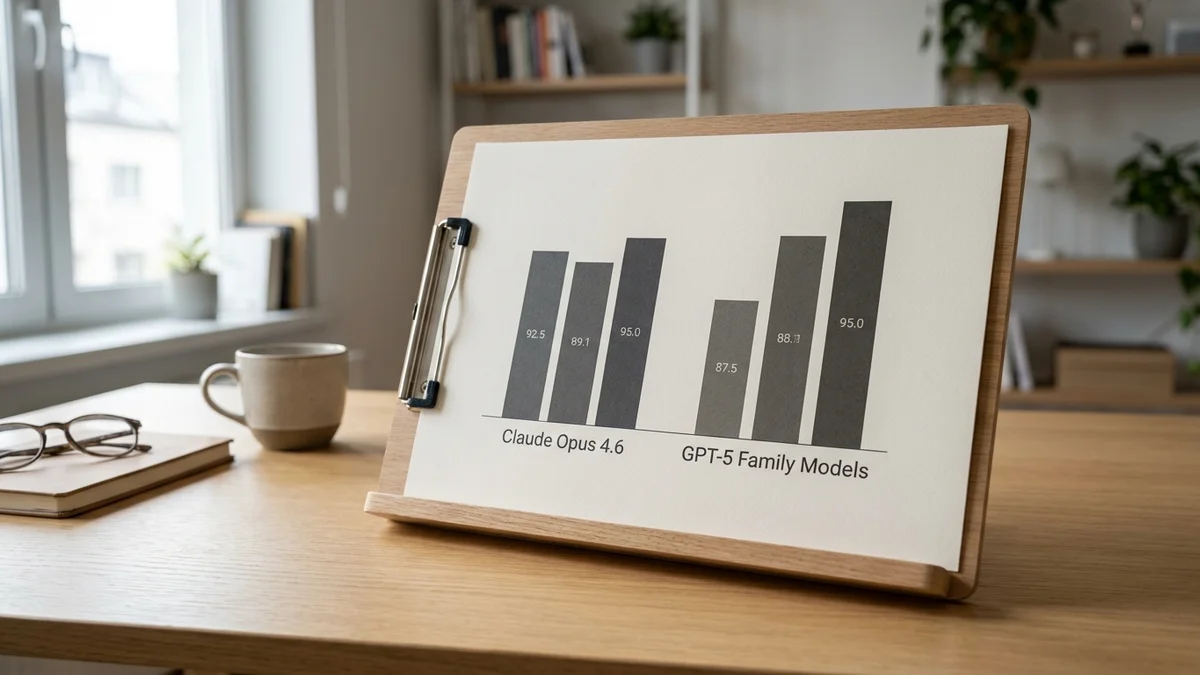
Coders and agent builders should default to Claude Opus 4.6. Researchers, mathematicians, and anyone running hard reasoning chains will get more out of GPT-5. Both are pricey. Neither is the cheapest option on the menu. But this fight isn't about saving money on tokens, it's about which frontier model actually finishes the job on the first try.
| Feature | Claude Opus 4.6 | GPT-5 (OpenAI flagship) |
|---|---|---|
| Context window | 200K tokens | 128K (GPT-4o baseline) |
| Input pricing | $5 / MTok | Check official pricing |
| Output pricing | $25 / MTok | Check official pricing |
| MMLU | High-90s (per Anthropic) | 88.7% (GPT-4o reference) |
| HumanEval | Low-90s (largely saturated) | 90.2% (GPT-4o reference) |
| SWE-bench Verified | 72% (with scaffold) | 69.1% (o3, OpenAI self-reported) |
| MATH | Mid-80s (Anthropic) | 96.7% (o3, self-reported) |
| GPQA Diamond | Mid-70s (Anthropic) | 87.7% (o3, self-reported) |
| ARC-AGI | Lower than o3 | 87.5% (o3 high compute, self-reported) |
| Chatbot Arena Elo | Top tier (see lmarena.ai) | Top tier (GPT-4o reference) |
| Best for | Coding, agents, writing | Reasoning, math, research |
A note on the GPT-5 column. OpenAI's public benchmark transparency has been spotty in 2026, and many widely-cited numbers still reference GPT-4o or the o3 reasoning model. Where the latest GPT-5 figures aren't published, the table cites the closest official OpenAI proxy.
If you write code for a living, this is the section that matters most. Claude Opus 4.6 is the highest-scoring model on SWE-bench Verified, the benchmark that runs models against real GitHub issues from real open-source repos. According to Anthropic's published results, Claude Opus 4.6 hits 72% on SWE-bench Verified with a proper scaffold. OpenAI's o3 lands at 69.1% on OpenAI's own self-reported runs (the public swebench.com leaderboard shows o3 at 58.4% under independent scaffolds).
That's a meaningful gap when you're shipping production code, not a rounding error.
On HumanEval, the older but still-cited Python coding benchmark, both Claude Opus 4.6 and GPT-4o sit in the low-90s — the benchmark is largely saturated, but the pattern of Claude leading on coding evaluations holds across most metrics.
Why does Anthropic keep winning here? A few reasons stand out:
This is also why Claude Code, Anthropic's CLI agent, has become the default tool for senior engineers running terminal-based workflows. Cursor, Windsurf, and Cline all default to Claude on their highest coding tier for the same reason.
And if you've spent any time in r/LocalLLaMA or developer Discords lately, the consensus from people doing actual production work is pretty consistent: Claude is better at finishing tasks. GPT-5 is better at thinking through problems abstractly. Both useful, different jobs.
But coding isn't everything. On pure reasoning benchmarks, OpenAI's reasoning lineage (o1, o3, and now GPT-5) opens up a real lead that you can't argue away.
On the MATH benchmark, OpenAI's reasoning models (o1, o3) reach the mid-90s on their self-reported runs, while Claude Opus 4.6 trails by roughly 10+ points. That's not a small gap, and it shows up again on graduate-level science questions.
On GPQA Diamond, the brutal PhD-level science test, o3 reports a clear lead over Claude Opus 4.6 (per OpenAI's self-reported numbers, the gap is roughly 10+ percentage points). If your workload involves reading research papers, doing chemistry derivations, or proving theorems, GPT-5 and its reasoning siblings will outperform Claude. The training pipeline OpenAI built around chain-of-thought RL is genuinely working on these problems.
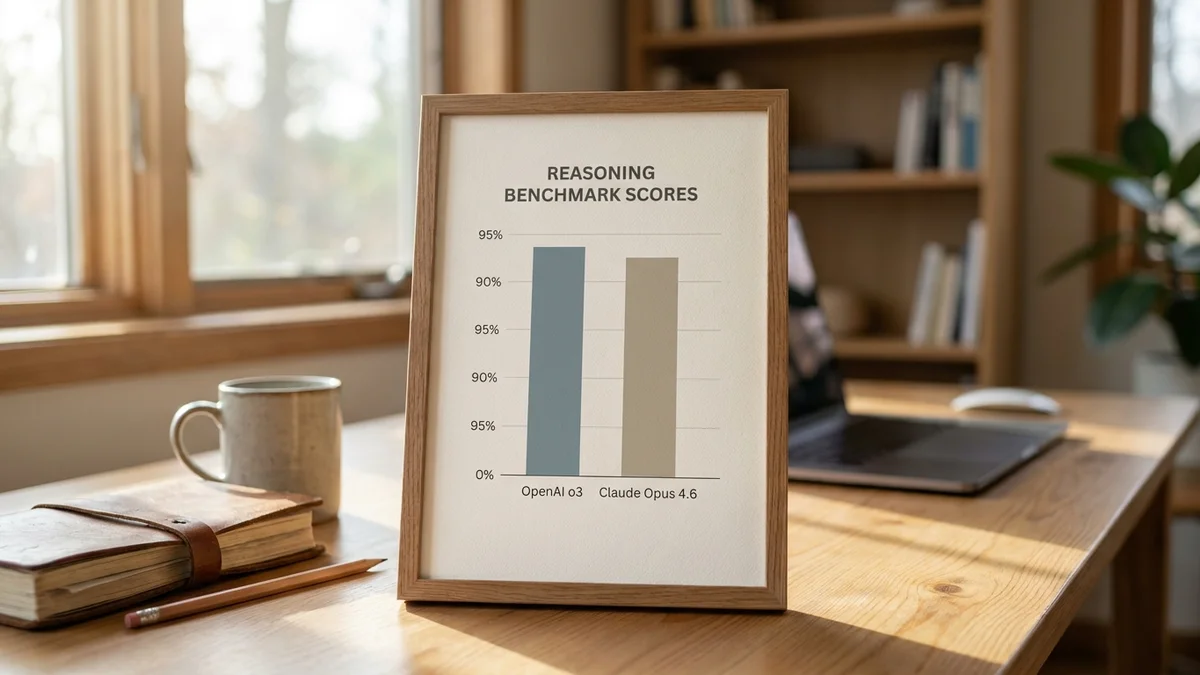
And then there's ARC-AGI, the abstract pattern-matching benchmark designed to resist memorization. o3 in high-compute mode reportedly hit 87.5% on ARC-AGI-1 (per the Dec 2024 announcement); Claude Opus 4.6 lands considerably lower. ARC-AGI is a controversial benchmark (it's expensive to run and o3's high score required massive inference compute), but the capability gap is real.
On GSM8K, the grade-school math word problems benchmark that's mostly saturated at this point, both models score in the high-90s. Both are basically maxed out.
Claude Opus 4.6 ships with a 200K context window as standard. That's roughly 500 pages of text in a single prompt. OpenAI's flagship lineup historically caps at 128K for the GPT-4o family, though specific GPT-5 limits depend on the tier you're on. Check the OpenAI docs for current numbers.
For practical work, 200K versus 128K matters when:
(Anthropic also offers prompt caching, which makes the long-context economics much more tolerable for repeated workloads.)
If you mostly chat and run short prompts, this won't matter much. But if you build agents or do bulk analysis, it's genuinely useful in ways the raw token number undersells.
As of early 2026, Claude Opus 4.6 prices at $5 per million input tokens and $25 per million output tokens. Anthropic's prompt caching can drop the effective input cost by up to 90% on repeated context, which makes Opus surprisingly competitive in agent loops where you're hitting the same system prompt thousands of times.
OpenAI's GPT-5 pricing depends heavily on the tier and the reasoning effort setting (low, medium, high). Reasoning models charge for "thinking tokens" you never see, which can balloon costs on hard problems. Check the OpenAI pricing page for current rates.
A rough rule of thumb based on developer reports: for typical coding workloads, Claude Opus 4.6 ends up cheaper per finished task even though the per-token rate looks high. For one-shot reasoning queries, GPT-5 can be cheaper if you stick to lower reasoning tiers.
Per-token pricing comparisons are mostly useless. What actually matters is cost per completed task, and that depends entirely on which model gets it right on the first try.
So treat any "Claude is 3x more expensive" headline with skepticism. Cost-per-token is a vanity metric in a world where model A solves a problem in one call and model B needs five.
Claude Opus 4.6 isn't the fastest model in Anthropic's lineup (Sonnet 4.6 is roughly 3x quicker), but it's responsive enough for interactive use. Streaming feels snappy, and time-to-first-token is generally under 2 seconds in most regions.
GPT-5's reasoning modes introduce noticeable latency. When you crank reasoning effort to "high," responses can take 30+ seconds for hard problems because the model genuinely thinks longer before producing output. That's a feature for math and research workloads, but it's painful in chat UIs where users expect instant feedback.

For real-time applications, both companies offer faster siblings. Claude Sonnet 4.6 and GPT-4o-class models cover the speed-sensitive tier. Most production teams use a tiered routing setup: cheap fast model for simple stuff, frontier model for the hard 5% of queries.
Subjectively, and based on Chatbot Arena Elo, the two models track closely in casual conversation, generally within a few Elo points of each other — well within the margin of preference variance and not really a meaningful quality signal.
Where they differ is tone:
If you want a model that asks clarifying questions before guessing, Claude wins. If you want a model that just produces an answer fast, GPT-5 wins. Neither is universally correct. It depends on whether your downstream cost of being wrong is high or low.
This is the area people undervalue. The model is half the story. The tooling around it determines whether you can actually ship.
Claude's ecosystem strengths:
GPT-5's ecosystem strengths:
For agent builders specifically, Claude's MCP and Anthropic's tool-use training give it the edge. For mainstream app integration, OpenAI's broader SDK and partner ecosystem still matters.
So who actually wins this fight? Genuinely depends on what you're shipping.
For production software engineering in 2026, Claude Opus 4.6 is the right pick. The SWE-bench Verified gap is too significant to ignore, the 200K context window is practically useful (not just a marketing number), and the agentic tooling around Claude has matured faster than OpenAI's coding stack. Most senior engineers running terminal workflows have already made this switch.
For pure reasoning, math, and abstract problem solving, GPT-5 and the o-series lineup win convincingly. The gap on MATH, GPQA Diamond, and ARC-AGI is real, and OpenAI's reasoning training pipeline has produced consistently better results on these workloads since o1 first launched.
Most serious teams don't actually pick. They use Claude for code and writing, GPT-5 for research and reasoning, and accept that they'll pay two API bills. That's the boring honest answer that most comparison articles refuse to give you.
And if you can only pick one model for everything? Claude Opus 4.6, by a hair. The coding lead matters more than the reasoning lead for most real workloads, and the context window covers more practical use cases than the math benchmark gap covers research ones.
Sources
Yes, through aggregator APIs. OpenRouter, Poe, and Together AI all expose both models behind a unified OpenAI-compatible endpoint, which lets you switch models with a single string change. Expect a 5-10% markup over native pricing in exchange for unified billing and rate limits.
Yes. Claude Opus 4.6 accepts image inputs through both the API and Claude.ai web interface, with capabilities roughly comparable to GPT-5 for chart reading, screenshot analysis, and document OCR. Anthropic supports JPEG, PNG, GIF, and WebP up to 5MB per image, with up to 100 images per request on the API.
For RAG, Claude Opus 4.6 has a structural advantage with its 200K context window and prompt caching, which lets you stuff more retrieved chunks into each query and cache the system prompt cheaply. GPT-5 wins if your RAG involves heavy reasoning over retrieved scientific content. For typical enterprise RAG over docs, Claude is usually the better default.
On the public swebench.com leaderboard, the most recent Sonnet (Claude 4.5 Sonnet) scores around 70% on SWE-bench Verified versus Opus 4.6's 72-76% range, but Sonnet costs $3/$15 per million tokens versus Opus's $5/$25 and runs roughly 3x faster. For most day-to-day coding, Sonnet is the better cost-performance pick. Reach for Opus on hard architectural problems or when Sonnet keeps failing on a specific task.
Both Anthropic and OpenAI use tier-based rate limits that scale with your monthly spend. New accounts start with low TPM (tokens per minute) caps and graduate automatically as usage grows. Hitting a limit returns a 429 error with retry guidance, not a charge. For production workloads, request a tier increase or use a multi-provider router like LiteLLM to spread load across both APIs.