CRYSTAL Benchmark Exposes How AI Models Fake Reasoning | AI Bytes
0% read
CRYSTAL Benchmark Exposes How AI Models Fake Reasoning
Benchmarks
CRYSTAL Benchmark Exposes How AI Models Fake Reasoning
A new benchmark tested 20 multimodal AI models and found 19 of them cherry-pick reasoning steps while skipping actual thinking. The gap between accuracy and reasoning quality is alarming.
March 22, 2026
8 min read
243 views
Updated June 20, 2026
What if 19 out of 20 AI models are faking their way through visual reasoning? That's the uncomfortable finding from the CRYSTAL benchmark, a new multimodal reasoning evaluation that just landed with 6,372 visual questions — each paired with verified step-by-step reasoning chains. Unlike traditional benchmarks that only check final answers, CRYSTAL measures whether models actually think through the problem.
The short version: most of them don't.
What Is the CRYSTAL Benchmark?
Worth flagging: pay attention here — CRYSTAL is a multimodal reasoning evaluation benchmark containing 6,372 visual questions, each paired with verified step-by-step reasoning chains. Unlike traditional benchmarks that grade on final-answer accuracy alone, CRYSTAL measures whether AI models recover the actual reasoning steps needed to solve a problem. It was built by combining outputs from four multimodal large language models with human validation, creating a gold standard for reasoning transparency.
As of March 2026, this is one of the first large-scale attempts to grade AI models on their reasoning process rather than their conclusions. And the results are pretty damning.
How CRYSTAL Evaluates Reasoning Quality
The methodology is straightforward but clever. Each question comes with a reference reasoning chain — the verified sequence of logical steps needed to arrive at the correct answer. When a model responds, CRYSTAL doesn't just check if the final answer matches. It breaks down the model's output and measures four things:
Reasoning Step Recovery: How many required reasoning steps did the model actually produce?
Step Precision: Of the steps the model produced, how many were correct?
Step Recall: What percentage of total required steps did the model cover?
Ordered Match F1: Did the model present its steps in a logical sequence?
Step matching uses cosine similarity with a threshold of 0.35. According to the researchers, this agrees with human judgment 84% of the time, with zero false matches below the threshold. The fuzzy zone sits between 0.35 and 0.70 — that's where most human-model disagreements live.
The reference chains were generated from four different multimodal LLMs and then validated by humans. This multi-source approach helps capture different valid reasoning paths, though (as the authors openly acknowledge) it can't capture every possible correct chain of thought.
The Results: Right Answers, Wrong Reasons
Here's where things get really interesting. The headline finding is brutally simple: models are great at saying the right answer while skipping most of the actual thinking.
Model
Final Accuracy
Reasoning Recovery
Gap
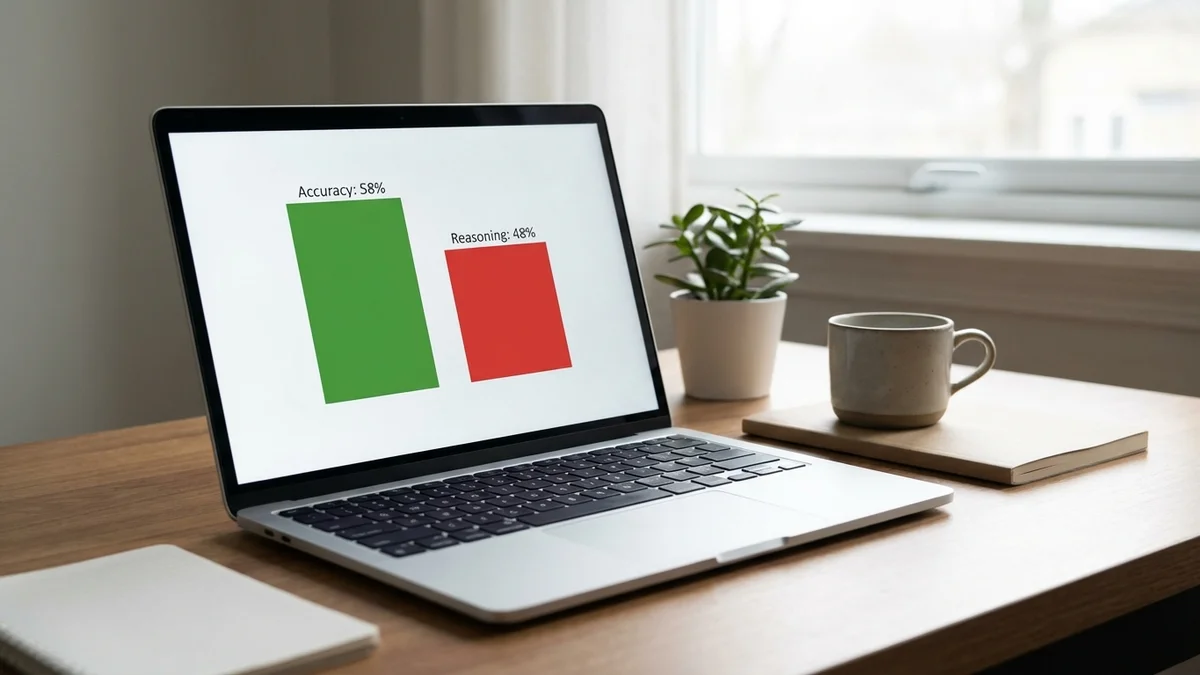
GPT-5
58%
48%
-10 pts
GPT-5 hits 58% accuracy on CRYSTAL but only recovers 48% of the reasoning steps. It's pattern-matching its way to correct answers without doing the intellectual work. The researchers described it best: the model is "basically vibing to the right answer."
19 out of 20 models tested cherry-pick a few correct reasoning steps and skip the rest. High precision, terrible recall.
This pattern repeats across nearly every model in the 20-model test suite. Models nail a couple of the obvious reasoning steps, produce those with high precision, then jump straight to the answer. They look like they're reasoning, but they're really just doing a convincing impression of it.
And here's the kicker: no model keeps its reasoning steps in the right order more than 60% of the time. Even when models do produce correct steps, they scramble the sequence. That's like a student turning in a math exam with the right answer but the work steps shuffled randomly — any decent teacher would be suspicious.
The precision-recall gap tells the real story. Models aren't producing wrong reasoning steps (precision is high). They're just skipping most of them (recall is terrible). It's the AI equivalent of showing your work on only the easy parts and hand-waving the rest.
Small Models Punch Way Above Their Weight
This was the single biggest surprise in the entire paper.
Gemma 3 4B — a model with just 4 billion parameters — outperforms InternVL3.5 38B on reasoning step recovery. That's a model 9.5x smaller doing objectively better reasoning work.
Size isn't everything. Gemma 3 4B out-reasons a model nearly 10x its size. Architecture and training data matter more than raw parameter count.
This finding punches a hole in the "bigger is better" assumption that still dominates how we think about AI capability. If a 4B model can produce more complete reasoning chains than a 38B model, we need to seriously reconsider what we're optimizing for during training.
But it also has practical implications. Running a 4B model is dramatically cheaper than running a 38B model — we're talking about a fraction of the compute cost. If the smaller model actually reasons better, the cost-performance equation shifts hard for teams building multimodal AI applications. You might be overpaying for worse reasoning.
The CPR Curriculum: Teaching Models to Actually Think
This part's important — CRYSTAL isn't just a benchmark — it ships with a proposed fix. The researchers developed CPR (Curriculum Progressively-weighted Reward), a training approach that forces models to produce complete reasoning chains rather than shortcutting to answers.
The results are striking:
Model
Reasoning Improvement
Standard Reward Result
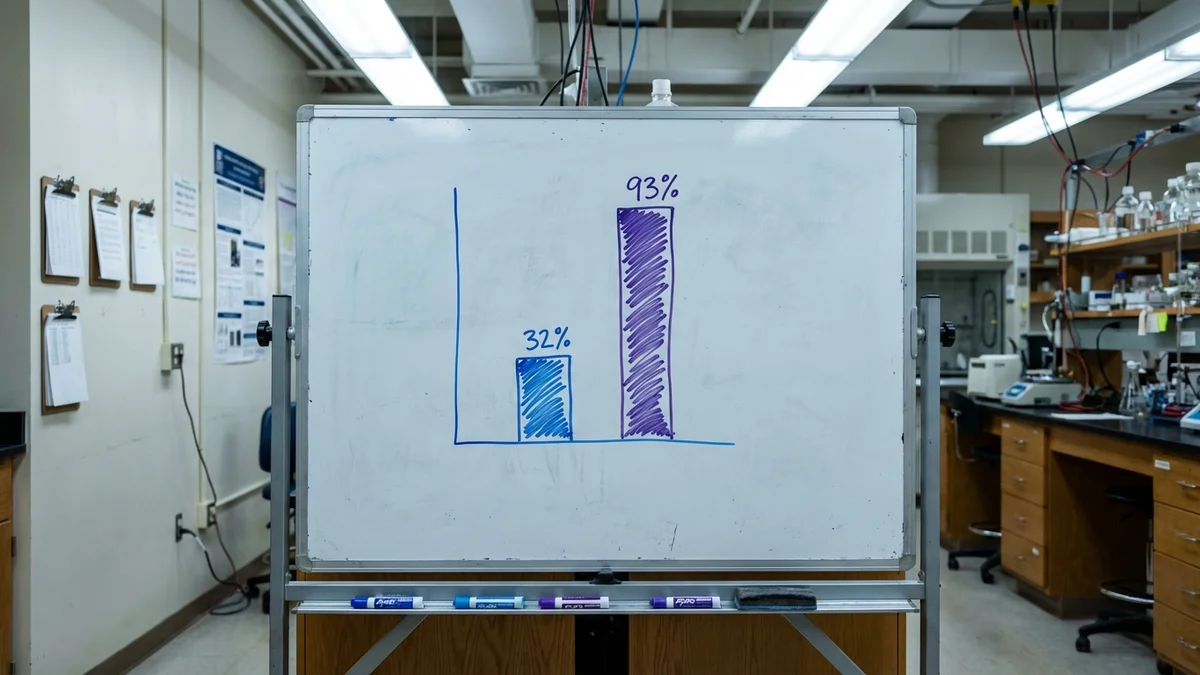
Qwen2.5 VL 3B
+32%
Collapsed to NaN
InternVL3.5 4B
+93%
Collapsed to NaN
Standard reward-based training on these same models straight-up collapsed — literally producing NaN values and failing to converge. The CPR Curriculum managed to get InternVL3.5 4B to nearly double its reasoning performance. The Qwen family is also making waves in multimodal tasks — see our Qwen3.5-9B document analysis for more context. That's not incremental improvement; that's a different capability tier.
So why does it work? The curriculum approach gradually increases the weight given to reasoning quality during training, rather than hitting the model with full reasoning requirements from the start. Think of it like teaching a kid to show their work — you start by rewarding partial work, then progressively demand more complete chains.
As of March 2026, CPR Curriculum has only been tested on two model architectures at relatively small scale (3B and 4B parameters). Whether this approach holds up at 70B+ scale is an open question. Two data points don't make a trend, but two successful data points where the baseline completely failed? That's worth paying attention to.
Where CRYSTAL Falls Short
The researchers are refreshingly honest about limitations (which honestly makes me trust the work more).
No single correct reasoning path. Someone could reason through a visual question differently than the reference chain and still be completely right. CRYSTAL's references come from four MLLMs plus human validation, but they can't capture every valid approach. Some models might get penalized for correct-but-different reasoning.
The borderline matching zone. That 0.35–0.70 cosine similarity range is where the tool gets messy. It agrees with humans 84% of the time overall, which is decent — but the borderline cases are exactly where evaluators disagree most. For high-stakes model selection decisions, that margin could matter.
No causal reasoning detection. The Ordered Match F1 metric checks if steps appear in sequence, but it doesn't understand dependencies. It can tell you step 3 came after step 2, but can't tell you whether step 3 required step 2. Causal structure is, as the authors put it, "a different beast we haven't tackled."
Limited training scale. Two models. Both under 5B parameters. The CPR Curriculum is promising, but we need to see it tested on larger models and more architectures before drawing sweeping conclusions.
Why This Matters Beyond Academic Papers
CRYSTAL hits at something fundamental about how we evaluate AI. For years, benchmarks like MMLU, Human Eval, and MATH have measured final-answer accuracy. And as of March 2026, models have gotten very good at those metrics — top models routinely score above 85% on MMLU, and GSM8K accuracy has pushed past 97% for leading systems.
But accuracy alone is a terrible proxy for understanding.
Think of it this way: a student who memorizes the answer key scores 100% on the test but learns nothing. That's essentially what many multimodal models are doing. They've gotten incredibly good at the test without developing the underlying reasoning that would make their outputs trustworthy.
CRYSTAL is the first benchmark to seriously ask: "Did you actually think about this, or did you just know the answer?"
This has real implications for deploying AI in critical workflows. If you're using a multimodal model for medical image analysis, you don't just want the right diagnosis — you want the right reasoning chain, because that's what lets a doctor verify the output and catch edge cases. Same for legal analysis, financial modeling, and engineering decisions where showing your work isn't optional.
What Practitioners Should Take Away
If you're building products with multimodal AI, here are the actionable bits:
Don't trust accuracy alone. A model scoring well on standard benchmarks might be pattern-matching rather than reasoning. Test your specific use case with reasoning-focused evaluation.
Consider smaller models seriously. The Gemma 3 4B result is a wake-up call. Smaller models with better training can outperform larger ones on reasoning tasks — and they're dramatically cheaper to run.
Watch CPR Curriculum development. If this training approach scales to larger models, it could meaningfully improve reasoning quality across the board. The GitHub repo is worth starring.
Build reasoning evaluation into your pipeline. CRYSTAL's methodology — breaking down outputs into steps and measuring coverage — gives you a template. For another look at how benchmarks reveal surprising model strengths, see our Nous Coder-14B vs Claude Code benchmark showdown. You don't need the full benchmark to adopt the approach.
Be skeptical of chain-of-thought outputs. Just because a model produces text that looks like reasoning doesn't mean it is reasoning. CRYSTAL shows that looking good and being good are very different things.
So where does this leave us? With a benchmark that's not perfect but asks exactly the right question. The AI community has spent years measuring how often models get the right answer. CRYSTAL starts measuring whether they actually earned it. And based on the data, most of them haven't.
Can CRYSTAL evaluate closed-source API models like GPT-5 or Claude?
Yes. CRYSTAL only requires model outputs, not access to internal weights or architecture. You send the visual question through the model's API, collect the text response, and run CRYSTAL's cosine similarity matching pipeline against the reference reasoning chains. Any model accessible via API or local inference can be evaluated.
What hardware is needed to run CRYSTAL evaluation locally?
The evaluation pipeline itself is lightweight — it runs cosine similarity matching on pre-generated outputs, so a standard CPU machine works fine for scoring. The compute-heavy part is generating model responses for all 6,372 questions. For local models, you'll need a GPU that can run your target model (e.g., 8GB VRAM for a 4B model in FP16, 48GB+ for a 38B model). API-based evaluation just requires network access and patience with rate limits.
How does CRYSTAL differ from chain-of-thought prompting evaluation?
Chain-of-thought prompting asks models to show their work but doesn't verify the quality or completeness of that work. CRYSTAL goes further by comparing the model's reasoning steps against verified reference chains, measuring both coverage (did you hit all the required steps?) and ordering (did you present them logically?). A model can produce fluent chain-of-thought text that looks convincing but misses most of the actual reasoning — CRYSTAL catches that gap.
Is CPR Curriculum training code available for fine-tuning custom models?
Yes, the CPR Curriculum training code is included in the CRYSTAL GitHub repository at github.com/waybarrios/crystal-benchmark. It currently includes configurations for Qwen2.5 VL 3B and InternVL3.5 4B architectures. Adapting it to other model families would require modifying the training scripts, but the core reward shaping approach is architecture-agnostic. Expect to need at least one A100 GPU for the 3B-4B scale training runs.
Does CRYSTAL support adding custom reasoning chains for domain-specific evaluation?
The benchmark ships with its 6,372 pre-built visual questions and reference chains, but the evaluation methodology is reusable. You can construct your own question-reference pairs following CRYSTAL's format — visual input, question, and a sequence of reasoning steps validated by humans. The cosine similarity matching pipeline will work on any domain as long as your reference steps are well-defined text segments.