Qwen3.5-9B Crushes GPT on Documents—But Has a Glaring Weak Spot
What if a 9 billion parameter open-source model could outperform GPT and Claude on document understanding tasks? According to recent benchmark results from the LocalLLaMA community, that's exactly what's happening—but only in specific document domains. This Qwen3.5-9B benchmark comparison breaks down exactly where the small model wins and where it falls flat.
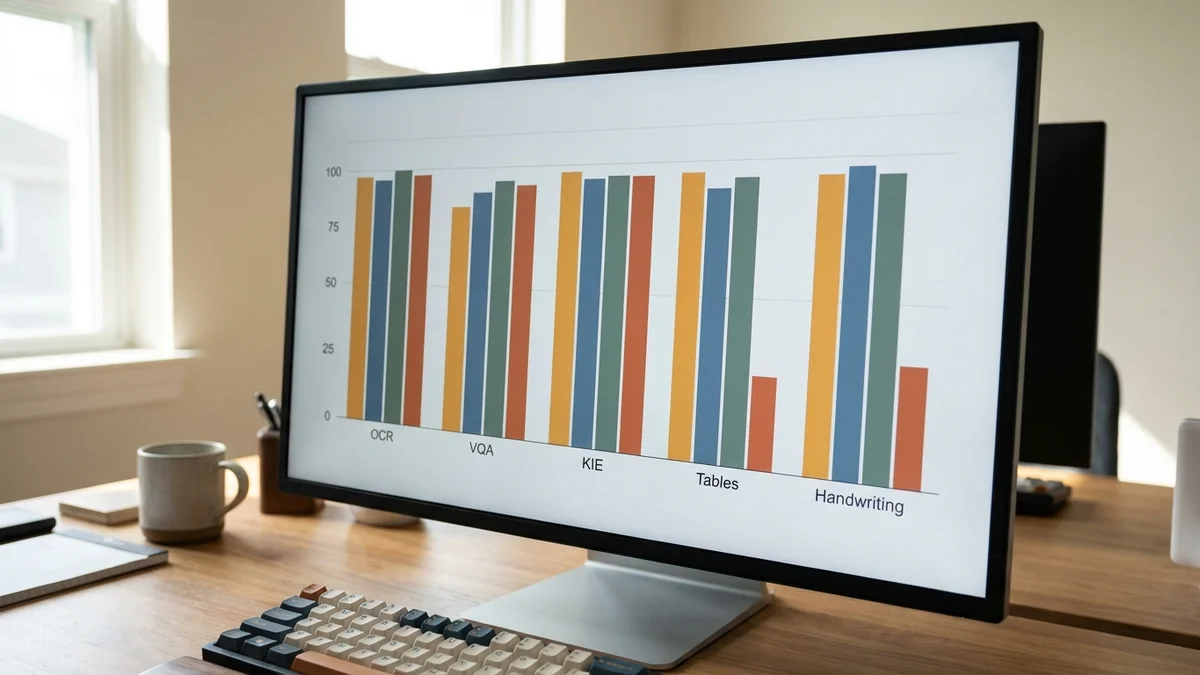
As of March 16, 2026, the Qwen3.5 family has been thoroughly tested across 9,000+ real-world documents in nine different task categories, as documented on the IDP Leaderboard. The results are messy. They're contradictory. And they're way more interesting than "small model is slower than big model."
Qwen3.5-9B isn't a universal document champion. But in text extraction and field extraction? It's genuinely competitive with models that cost 100x more to run via API. That's worth understanding if you're building a local document processing pipeline.
Quick Verdict: When to Use What
Use Case
Best Choice
Runner-Up
Why
Text extraction (OCR)
Qwen3.5-9B (78.1)
Gemini 3.1 Pro (74.6)
Qwen wins across all sizes; production-ready for messy PDFs
Question answering on docs
Gemini 3.1 Pro (85.0)
Qwen3.5-9B (79.5)
Qwen edges GPT-5.4 by 1.3 points; closes frontier gap significantly
Invoice/form field extraction
Gemini 3 Flash (91.1)
Qwen3.5-9B (86.5)
Qwen matches Gemini 3.1 Pro; beats GPT mini models
Table extraction
Gemini 3.1 Pro (96.4)
Claude Sonnet 4.6 (96.3)
Qwen maxes out at 76.6—clear architectural weakness
Handwriting recognition
Gemini 3.1 Pro (82.8)
GPT-4.1 (75.6)
Qwen trails by 17 points; not suitable for handwritten docs
Cost-optimized local processing
Qwen3.5-4B (77.2 OCR)
Qwen3.5-2B
4B model is 95% of 9B's performance at half the VRAM
The core insight: Qwen3.5-9B punches above its weight class on extraction tasks but hits an invisible ceiling on structured data (tables). This isn't about model size—it's about training data and architecture.
Qwen3.5-9B Benchmark Comparison: Where It Actually Wins
This is Qwen's strongest domain. The benchmark tests text extraction from dense PDFs, multi-column layouts, and poor-quality scans—the kind of real-world chaos that breaks most document AI systems.
As of March 16, 2026:
Model
OlmOCR Score
Delta from Qwen-9B
Qwen3.5-9B
78.1
—
Qwen3.5-4B
77.2
-0.9
Gemini 3.1 Pro
74.6
-3.5
Claude Sonnet 4.6
74.4
-3.7
GPT-5.4
73.4
-4.7
Qwen3.5-2B
73.7
-4.4
Why does a smaller model beat Gemini and Claude here? Two factors:
Training data focus. Qwen3.5 was explicitly trained on OCR-heavy datasets. Frontier models treat document images as one of many tasks in a massive, generalist training corpus.
Architecture design. Qwen's token efficiency on dense visual sequences appears to outperform larger models that need more reasoning overhead for the same task.
And here's the kicker—the 4B model is only 0.9 points behind the 9B. For local deployment, that changes the calculus entirely. You get near-identical OCR performance at a fraction of the memory footprint.
If you're extracting text from scanned documents at scale, Qwen3.5-9B is the best open model available. Full stop.
2. Visual Question Answering on Documents (VQA)
This benchmark tests whether the model can answer questions about document content—tables, charts, text blocks, anything visual in a PDF.
As of March 16, 2026:
Model
VQA Score
Delta
Gemini 3.1 Pro
85.0
—
Qwen3.5-9B
79.5
-5.5
GPT-5.4
78.2
-6.8
Qwen3.5-4B
72.4
-12.6
Claude Sonnet 4.6
65.2
-19.8
Gemini 3 Flash
63.5
-21.5
This one's surprising. The 9B model is second only to Gemini 3.1 Pro and beats GPT-5.4 by 1.3 points. It crushes Claude Sonnet by 14 points. That's not a rounding error—that's a meaningful, production-relevant gap.
The gap between 4B and 9B here (7.1 points) tells a different story than OCR. Visual reasoning scales harder than pure text extraction. But even the 4B hitting 72.4 is respectable. And you definitely want the 9B for VQA tasks.
3. Key Information Extraction (KIE)—Invoices & Forms
KIE tests the model's ability to pull specific fields from documents: invoice numbers, dates, amounts, vendor names, line items.
As of March 16, 2026:
Model
KIE Score
Notes
Gemini 3 Flash
91.1
Tiny model punching hard
Claude Opus 4.6
89.8
Strongest Claude variant here
Claude Sonnet 4.6
89.5
Still excellent
GPT-5.2
87.5
Mid-tier GPT
Gemini 3.1 Pro
86.8
—
Qwen3.5-9B
86.5
Matches Gemini 3.1 Pro
Qwen3.5-4B
86.0
Essentially production-equivalent
GPT-5.4
85.7
—
Qwen3.5-9B ties Gemini 3.1 Pro and sits ahead of GPT-5.4 and Claude Haiku 4.5. This is the "use case that actually matters" for most enterprises—invoices, receipts, contracts. A 9B open model that matches frontier performance is a cost-saving home run.
And again, the 4B model is only 0.5 points lower. That's basically noise in production systems.
This is Qwen's ceiling, and it's depressing to look at.
Model
GrITS Score
Delta
Gemini 3.1 Pro
96.4
—
Claude Sonnet 4.6
96.3
-0.1
Gemini 3 Pro
95.8
-0.6
GPT-5.4
94.8
-1.6
GPT-5.2
86.0
-10.4
Gemini 3 Flash
85.6
-10.8
Qwen3.5-9B
76.6
-19.8
Qwen3.5-4B
76.7
-19.7
Frontier models score between 85–96. Qwen maxes out at 76.7. The truly revealing part: the 4B and 9B scores are essentially identical. This isn't a scale problem. This is an architecture or training data problem.
Qwen was not trained on tables. Or it was trained on tables in a way that doesn't transfer to complex, real-world table layouts. Whatever the reason, tables are a hard no for Qwen3.5 right now.
If table extraction is in your document pipeline, you need a frontier model or a specialized tool. Qwen won't cut it.
Handwriting Recognition
Model
Handwriting OCR Score
Gemini 3.1 Pro
82.8
Gemini 3 Flash
81.7
GPT-4.1
75.6
Claude Opus 4.6
74.0
Claude Sonnet 4.6
73.7
GPT-5.4
69.1
Ministral-8B
67.8
Qwen3.5-9B
65.5
Qwen3.5-4B
64.7
Qwen trails by 17 points versus Gemini 3.1 Pro. Not production-ready for handwritten documents. If your use case involves signed forms, doctor's notes, or handwritten annotations, Qwen isn't the answer.
The Architecture & Training Story
Why does Qwen dominate text extraction but fail at tables? The answer lies in how Qwen3.5 was built.
OCR-centric pretraining — The model saw massive amounts of scanned documents, low-resolution images, and noisy text. Gemini and Claude saw that data too, but as a smaller slice of a broader mix.
Visual token efficiency — Qwen uses fewer tokens to encode visual information than competing architectures. This makes it faster and more accurate on text-in-images, but it may sacrifice precision on structured visual information like table cells, cell boundaries, and alignment.
Training data composition — Qwen was trained on documents from Alibaba's ecosystem, which skews heavily toward forms, invoices, and receipts. It was not optimized for academic tables or complex spreadsheet-style data.
Frontier models (GPT-5.4, Claude Sonnet 4.6, Gemini 3.1 Pro) treat documents as one task among hundreds. They have more model capacity and more diverse training data. They can solve any document task—just not necessarily with the same efficiency as a model purpose-built for that task.
Qwen3.5-9B is the opposite: highly specialized, narrowly excellent.
Performance Comparison: Head-to-Head on Key Metrics
Qwen wins decisively on OCR and comes in a strong second on VQA. Gemini wins 3 categories outright (VQA, tables, handwriting). Claude takes field extraction. GPT-5.4 doesn't top any category. But factor in cost, and Qwen's value proposition on OCR and field extraction is unmatched.
Practical Implications: Cost & Inference Speed
Qwen3.5-9B doesn't just win on benchmarks—it wins on economics.
API Costs (per 1M input tokens):
GPT-5.4: ~$2–$10/MTok (varies by tier; check openai.com/pricing)
Claude Sonnet 4.6: $3/MTok input
Gemini 3.1 Pro: $2–$4/MTok input (varies by prompt length)
Qwen3.5-9B (local): $0 (requires ~12–15GB VRAM at 8-bit quantization)
If you process 1 million documents per month with OCR + field extraction, running Qwen3.5-4B locally costs you roughly $200–$500/month in GPU cloud time. The same workload via frontier model APIs could cost $3,000–$10,000/month depending on the provider.
That's not a nice-to-have difference. That's a business model difference.
Use Cases: When to Pick Qwen3.5-9B vs. Frontier Models
✅ Use Qwen3.5-9B Local Deployment If:
High-volume OCR. Processing 100k+ documents monthly with text extraction as primary task. Qwen's accuracy + local speed = unbeatable.
Invoice/receipt processing at scale. Qwen matches frontier models on KIE and costs dramatically less. This is the killer app.
Private documents. Data sensitivity = can't use APIs. Qwen gives you 86% of Gemini's performance, locally.
Budget constraints. You need reasonable accuracy but APIs blow the budget. Qwen3.5-4B is the sweet spot: 95% of 9B's performance, half the VRAM.
Hybrid workflows. Use Qwen for extraction (OCR + field filling), then send structured results to a frontier model for reasoning. This cuts API calls by 70%.
❌ Use Frontier Models If:
Tables are critical. Qwen scores 76–77. Your documents have complex tables? You need Claude or Gemini (95+).
Handwritten content. Qwen's 65.5 isn't production-ready. Gemini 3.1 Pro at 82.8 is the clear choice.
You need one model for everything. Frontier models are generalists. Qwen is a specialist. If your pipeline has mixed document types, the frontier model's flexibility may outweigh its cost.
Complex reasoning on documents. Visual Q&A where the answer requires multi-step reasoning. Gemini 3.1 Pro (85.0) still beats Qwen (79.5).
The Verdict: Not a Replacement, but a Serious Alternative
Qwen3.5-9B doesn't replace frontier models. It displaces them in specific, high-volume use cases where it's demonstrably better at the task and dramatically cheaper.
As of March 16, 2026, this is the competitive market:
For text extraction: Qwen3.5-9B is the best model available. Period.
For field extraction: Qwen matches Gemini 3.1 Pro and beats GPT variants. If you're paying per token, switch to Qwen.
For visual Q&A: Qwen closes the gap with frontier models. It's no longer a tier-two option.
For tables & handwriting: Frontier models are still mandatory.
The honest take from this Qwen3.5-9B benchmark comparison? If you're building a document processing system in 2026, you now have a real choice. You don't have to use an expensive API. You can run 9B parameters locally, get world-class OCR and field extraction, and pocket the cost savings.
That's a meaningful shift in what's practical for enterprise document AI.
Sizing Guide: 9B vs. 4B vs. 2B
One more decision to make in this Qwen3.5-9B benchmark comparison: which size?
Model
VRAM (8-bit)
OCR Score
VQA Score
KIE Score
Inference Speed
Recommendation
Qwen3.5-2B
~4–5GB
73.7
N/A
~85
150+ tok/s
Budget tier, field extraction only
Qwen3.5-4B
~7–8GB
77.2
~72.4
86.0
80–100 tok/s
Best cost/performance ratio
Qwen3.5-9B
~12–15GB
78.1
79.5
86.5
40–60 tok/s
Production-grade OCR + VQA
Our pick:Qwen3.5-4B for most workloads. The 9B buys you 0.9 points on OCR and 7 points on VQA, but costs 2x the VRAM and runs 2x slower. Unless you're specifically optimizing for maximum accuracy, the 4B is the sweet spot.
But if you have the GPU hardware and your documents are genuinely messy (multi-language, poor scan quality, dense layouts), the 9B's 78.1 OlmOCR score justifies the extra resources.
Does Qwen3.5-9B really beat GPT-5.4 and Claude on document tasks?
It depends on the task. Qwen3.5-9B beats both on OCR (78.1 vs 73.4 GPT-5.4, 74.4 Claude Sonnet 4.6) and matches or exceeds them on field extraction (86.5 vs 85.7 GPT, 89.5 Claude). But it loses decisively on table extraction (76.6 vs 94.8 GPT, 96.3 Claude Sonnet 4.6) and handwriting (65.5 vs 69.1 GPT, 73.7 Claude Sonnet 4.6).
Should I use Qwen3.5-4B or Qwen3.5-9B for document processing?
Use Qwen3.5-4B unless you specifically need maximum OCR or VQA accuracy. The 4B scores 77.2 on OCR (only 0.9 points behind the 9B), runs at 2x the speed, and uses half the VRAM. Cost per token is essentially zero, so speed matters more than model size for most enterprises.
Why does Qwen fail at table extraction when it crushes OCR?
This appears to be an architecture or training data limitation, not a scale problem—both Qwen3.5-4B and 9B max out around 76.6 on GrITS. Qwen was trained heavily on OCR and form documents but was not optimized for table understanding. Frontier models with broader training data handle tables much better (95+).
What's the cost difference between running Qwen locally vs. Claude/GPT APIs?
Qwen3.5-9B local: ~$200-500/month cloud GPU. Claude Sonnet 4.6 API: ~$3,000–$5,000/month for equivalent volume (1M documents). GPT-5.4: ~$2,000-10,000/month. Local open models save 80–90%+ on high-volume document processing.
Can Qwen3.5-9B handle my document pipeline if it includes tables and handwriting?
No. Use Qwen for OCR and field extraction (where it excels), then pass results to a frontier model (Claude, Gemini, GPT) for table extraction or handwritten content. This hybrid approach cuts API costs by 70% while maintaining accuracy where needed.
Is Qwen3.5-9B production-ready for invoices and receipts?
Yes. On key information extraction (KIE), Qwen3.5-9B scores 86.5, matching Gemini 3.1 Pro and beating GPT-5.4 (85.7). It's production-grade for field extraction workloads and dramatically cheaper than API alternatives.