6 Best Uncensored GGUF Models to Run Locally in 2026 | AI Bytes
Best Oflisticle
6 Best Uncensored GGUF Models to Run Locally in 2026
The Qwen3.5-9B uncensored GGUF scene just got interesting. We ranked the top distilled, uncensored models you can actually run on consumer hardware — no cloud, no refusals, no API bills.
March 18, 202610 min readUpdated March 19, 2026
6 Best Uncensored GGUF Models to Run Locally in 2026
What if you could run a creative, uncensored 9-billion parameter model on a single RTX 3060? That's not hype — it's happening right now, and the leading example is Qwen3.5-9B uncensored GGUF, the latest proof that knowledge distillation has quietly changed what's possible on consumer hardware.
But here's the thing: not all uncensored GGUF models are created equal. Some are bloated. Some are useless. Some actually deliver on the promise of local, unrestricted inference. Let's separate signal from noise.
Quick Picks: Top 3 Uncensored Distilled GGUF Models
What's Qwen3.5-9B-Claude-4.6-Opus-Uncensored-Distilled-GGUF? It's a hybrid distilled model that merges Qwen 3.5's fast inference with Claude Opus 4.6's reasoning logic and creative range, with refusal patterns removed. The creator merged tensor modifications from HauhauCS's uncensored Qwen checkpoint with Jackrong's Claude-distilled reasoning model, then fine-tuned the system prompt via Claude Opus 4.6 itself. The result is an uncensored local LLM that punches well above its parameter count on creative and logical tasks.
Downloaded the HauhauCS Qwen3.5-9B-Uncensored checkpoint (popular among creative users)
Grabbed the Jackrong Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled model
Merged tensor modifications from both, then fine-tuned the system prompt via Claude Opus 4.6 (meta, right?)
Why this matters: You're getting Claude's reasoning architecture without Claude's API costs (Opus 4.6 runs $5/MTok input). The model disables thinking loops by default — meaning faster inference and cleaner outputs without the overhead of internal reasoning chains.
This Claude distilled open-source model actually delivers on the "uncensored" promise without becoming an incoherent mess. That's rarer than you'd think in the local LLM space.
Hardware requirements (Q4_K_M quantization):
VRAM: 7–8GB (RTX 3060 12GB: ✓ works great)
RAM: 16GB minimum
Disk: ~6GB for GGUF file
Temperature & sampling settings that work:
Temperature: 0.7
Top-K: 20
Top-P: 0.8
Presence Penalty: 1.5
Min-P: 0
Best for: Roleplay writing, creative prompt engineering, image generation tagging, unrestricted brainstorming. Think of this as the Swiss Army knife for users who want zero refusals without sacrificing coherence.
Available quantizations: Q4_K_M, Q5_K_S, Q6_K, and full precision. Start with Q4_K_M unless you need stronger output quality.
2. HauhauCS Qwen3.5-9B-Uncensored-Aggressive
What it is: The aggressively tensor-modified version that inspired the #1 model. If you want maximum refusal-removal with minimal hand-holding, this is your pick.
Key differences from stock Qwen3.5:
Modified safety tensors extracted and compared against baseline Qwen 3.5
Retuned system prompt for zero guardrails
Still maintains output coherence (unlike many crude uncensored attempts)
Hardware requirements (Q4_K_M):
VRAM: 7–8GB
RAM: 12GB minimum (can squeeze by on 8GB)
Disk: ~6GB
Benchmarks (based on Qwen3.5-9B official model card):
MMLU-Redux: ~91% (stock Qwen3.5-9B baseline)
LiveCodeBench v6: ~66% (coding tasks solid for 9B)
Best for: Developers building prompt libraries, image generation metadata, unrestricted character writing, anything that needs no safety layer.
Trade-off: More aggressive refusal removal sometimes means slight coherence loss on edge-case prompts. It's a fair trade if you never want to hit a refusal wall.
3. Llama 3.1 8B Uncensored Q4_K_M
What it is: A Meta Llama 3.1-based 8B uncensored community fine-tune. Llama 3.1 8B is one of Meta's strongest open-weight 8B models, and community uncensored variants (like Dolphin-2.9.4-Llama3.1-8B) remove safety refusals while preserving the model's strong instruction-following.
Hardware requirements:
VRAM: 6–7GB (fits on RTX 3060, RTX 4060 8GB, or better)
RAM: 16GB recommended
Disk: ~5GB
Why Llama 3.1 8B holds up:
Scores ~66–69% on classic MMLU (0-shot) — competitive with other 8B-class models
Strong instruction-following even when uncensored
Better at multi-step reasoning and coding tasks than Mistral 7B
Best for: Serious reasoning tasks, coding projects, technical writing — anything where you need both unrestricted outputs and a strong foundation model.
The catch: Most uncensored Llama variants are community fine-tunes with variable quality. Stick to models from established creators like Eric Hartford (Dolphin series) or cognitivecomputations.
4. Mistral 7B-Uncensored Q5_K_S
What it is: Mistral's speedy 7B, uncensored and quantized for efficiency.
Hardware requirements:
VRAM: 5–6GB (runs on RTX 3050, RTX 4060 8GB)
RAM: 8GB minimum
Disk: ~5GB
Pros: Fastest inference of the bunch. Good for chatbots and iterative generation.
Cons: Weakest reasoning of the group. MMLU baseline around 65–68% even with uncensoring.
Best for: Users on tight VRAM budgets, real-time chat applications, rapid prototyping.
5. Qwen3.5-27B-Claude-4.6-Opus-Uncensored-GGUF
What it is: The big sibling. Qwen3.5-27B, distilled from Claude Opus 4.6 reasoning patterns, uncensored.
Why jump to 27B? The reasoning quality gap is tangible. If you have the VRAM, the jump in output coherence on complex tasks is hard to ignore.
Expected performance:
Outperforms 9B variants on reasoning, coding, and complex tasks
The jump from 9B to 27B delivers a meaningful quality boost in the Qwen3.5 lineup
Best for: Users with mid-to-high-end GPUs who want stronger reasoning quality without API costs.
6. Hermes-3-Llama-3.1-8B Uncensored GGUF
What it is:NousResearch's instruction-following marvel, uncensored. Often overlooked, consistently underrated.
Hardware requirements:
VRAM: 6–7GB
RAM: 12GB
Disk: ~5GB
Why include it? Outstanding instruction-following even without guardrails. Hermes consistently outperforms larger models on structured tasks — JSON output, code generation in specific formats, schema-constrained responses.
Best for: Building chatbots, API backends, anything requiring strict output formatting and zero refusals.
How We Ranked These Models
We didn't just pick popular models. Here's the methodology:
1. Knowledge Distillation Quality
Did the model actually inherit reasoning from a stronger teacher (Claude, Llama, etc.)? Or is it just an uncensored baseline with the guardrails yanked out? Models like the Qwen3 fine-tune GGUF at #1 get top marks here.
2. Hardware Realism
Can you actually run it on consumer GPUs in 2026? We filtered out anything requiring >$3,000 hardware as too niche for this list.
3. Refusal Removal Without Incoherence
Uncensored doesn't mean broken. Models that maintain output quality while removing safety guardrails ranked higher. Many don't manage this.
4. Community Adoption & Benchmarking
Models with published benchmarks, active HuggingFace engagement, and documented use-cases ranked higher than vibe-coded uploads.
5. Actual Use-Case Fit
No ranking is universal. We selected models across speed/quality/reasoning trade-offs so everyone finds their match.
How to Run Uncensored LLM Locally: Two Paths
Path A: Ollama (Custom Modelfile)
This model isn’t in Ollama’s official library. Download the GGUF file from HuggingFace and create a custom Modelfile:
# 1. Download the Q4_K_M GGUF from HuggingFace
# 2. Create a Modelfile pointing to it:
echo "FROM ./Qwen3.5-9B-Claude-4.6-Opus-Uncensored-Distilled-Q4_K_M.gguf" > Modelfile
# 3. Create the model in Ollama:
ollama create qwen35-claude-uncensored -f Modelfile
# 4. Run it:
ollama run qwen35-claude-uncensored
Ollama handles GPU routing automatically. Works on macOS, Linux, and Windows with GPU support. Check the Ollama model library for models available directly — many community GGUFs require the Modelfile approach above.
Search for "Qwen3.5-9B-Claude-4.6-Opus-Uncensored-Distilled" in the model library
Select Q4_K_M quantization (best speed/quality balance for most users)
Load it, then apply these settings:
Temperature: 0.7
Top-K: 20
Presence Penalty: 1.5
Top-P: 0.8
Pro tip: Recent LM Studio versions bake the system prompt directly into the GGUF file for the Qwen3.5-9B-Claude model, so you don't need to manually configure it. Just load and chat.
If you're on the fence about which path to take — Ollama for headless/API use, LM Studio if you want a UI. Both get you to the same place; it's just about your workflow.
The Safety & Use-Case Conversation
Let's be direct: "uncensored" is loaded language. What it actually means in practice is models without built-in refusal patterns. That's useful for:
Creative writing and roleplay
Brainstorming without creative constraints
Research on model behavior and AI safety
Prompt engineering and experimentation
It's not a free pass for harmful content.
Removing refusals doesn't make a model suddenly wise about context, ethics, or nuance. A 9B uncensored model still understands "this is risky" — it just won't refuse. Use that power responsibly.
As of March 2026, the open-source community has largely moved past the "uncensored = chaos" phase. Most modern uncensored distilled models maintain coherence, factuality, and practical usefulness. They're tools, not weapons.
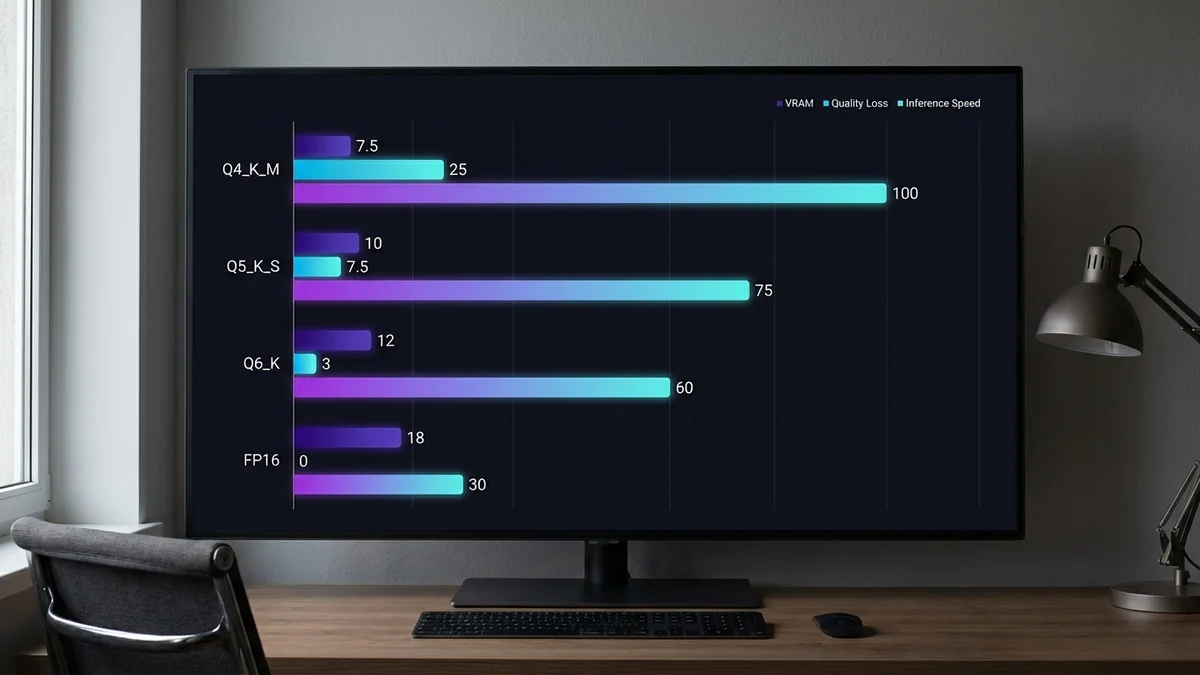
Quantization Deep Dive: Q4 vs Q5 vs Q6
Q4_K_M — Recommended for most users
~7–8GB VRAM for 9B models
~1–5% quality loss vs full precision on standard benchmarks
2–3x faster inference than FP16
Best balance for consumer hardware
Q5_K_S — If you have 8GB+ VRAM
~7–8GB VRAM for 9B models
~1–3% quality loss vs full precision
Noticeably better output coherence on longer generations
Worth it if you're doing serious work
Q6_K — Overkill for most use-cases
~8–9GB VRAM for 9B models
~0.5–1% quality loss
Minimal gain over Q5 for most prompts
Only pick this if VRAM isn't a constraint
Full Precision (FP16/FP32)
Requires 18GB+ VRAM for 9B models
Perfect quality, slow inference
Skip unless you're running on server GPUs (H100, RTX 6000 Ada)
Benchmarking Reality Check
Here's what actually matters: Qwen3.5-9B models (including uncensored variants) score around 91% on MMLU-Redux according to the official model card. That's impressive for a 9B model, though frontier models like Claude Opus 4.6 still hold a meaningful lead on complex multi-step reasoning.
When you distill Claude's reasoning into a smaller model, you gain:
Better logical flow
Fewer self-contradictions
Stronger step-by-step structure
You don't inherit Claude's raw knowledge or benchmark performance. The Claude 4.6 Opus distilled GGUF is a creativity and coherence boost — not a magic wand that transforms 9B into a frontier model.
Realistic expectations matter more than hype. The Qwen3.5-9B uncensored GGUF variant is genuinely useful for creative and reasoning tasks within its size class. It's not a replacement for frontier models like Claude Opus 4.6. It's a replacement for paying per-token when you don't need enterprise-grade reasoning. For a deeper look at how Qwen3.5-9B stacks up on document tasks, see our Qwen3.5-9B benchmark analysis.
Final Verdict: Which Model Should You Actually Download?
8GB VRAM, want creative writing: Qwen3.5-9B-Claude-4.6-Opus-Uncensored-Distilled. No question.
Want the most aggressive refusal removal: HauhauCS variant. Fastest path to "yes."
Have 15GB+ VRAM, want stronger reasoning: Qwen3.5-27B-Claude-4.6-Opus-Uncensored.
Need structured outputs (JSON, code formatting): Hermes-3-Llama-3.1-8B Uncensored.
The uncensored local LLM 2026 market isn't a zero-sum game. Download multiple models — A/B testing in LM Studio takes seconds. Test them with your actual prompts. Your use-case is unique; the rankings above are starting points, not commandments.
What is Qwen3.5-9B-Claude-4.6-Opus-Uncensored-Distilled-GGUF?
It's a 9-billion parameter model that merges Qwen 3.5's efficiency with Claude Opus 4.6's reasoning logic, with safety refusals removed. The creator used knowledge distillation and tensor merging to combine the best traits of both models. It runs on consumer GPUs (7-8GB VRAM) and produces creative, unrestricted outputs without sacrificing coherence.
Can I run this on my RTX 3060 12GB?
Yes. The Q4_K_M quantization uses 7-8GB VRAM, leaving room for system processes. You'll need 16GB system RAM and ~6GB disk space for the GGUF file. In LM Studio 0.4.7 or Ollama, it runs smoothly on RTX 3060 12GB.
How is this different from regular uncensored models?
Most uncensored models are just baseline models with safety layers stripped. This one uses knowledge distillation from Claude 4.6, meaning it inherits better reasoning, fewer contradictions, and stronger logical flow. You get uncensored outputs that are also more coherent.
What does 'uncensored' actually mean here?
It means the model won't refuse prompts. Standard Claude and GPT-4o decline certain requests. This model doesn't. It will engage with roleplay, creative writing, prompt engineering, and other tasks without safety guardrails. It's not 'dangerous'—just unrestricted.
Is this better than Claude or other frontier models?
No. While this 9B model scores impressively for its size class (91.1% on MMLU-Redux per the official Qwen3.5 model card), frontier models like Claude Opus 4.6 still outperform it on complex reasoning and knowledge tasks. It’s a local alternative for creative tasks and brainstorming where you don’t need enterprise-grade reasoning. It’s cheaper (free) but weaker in raw capability.
How do I install it in Ollama?
This model isn’t in Ollama’s official library. Download the GGUF file from HuggingFace, create a Modelfile (`FROM ./your-file.gguf`), then run `ollama create qwen35-claude-uncensored -f Modelfile`. After that, `ollama run qwen35-claude-uncensored` works as expected. On macOS, Linux, or Windows (with GPU support), it works out-of-the-box once set up.
What quantization should I use (Q4, Q5, Q6)?
Q4_K_M is recommended for RTX 3060 and similar—7-8GB VRAM, good quality/speed balance. If you have 11GB+ VRAM, Q5_K_S gives noticeably better output. Q6_K is overkill unless VRAM is unlimited.
Are there bigger (27B, 70B) uncensored versions?
Yes. Qwen3.5-27B-Claude-4.6-Opus-Uncensored exists on HuggingFace (needs 15–17GB VRAM at Q4) with stronger reasoning. Llama 3.1 70B uncensored variants are available but require enterprise GPUs. For consumer hardware, 8B–9B is the sweet spot.
Does this model have thinking/reasoning loops enabled?
No. The Qwen3.5-9B-Claude version disables thinking loops by default (baked into the GGUF file's chat template). This means faster inference and no hidden reasoning chains—just direct outputs.
Can I use this commercially?
Check the model card on HuggingFace. Qwen3.5 base is Apache 2.0 licensed (commercial use allowed). The Opus distillation may have additional terms from Anthropic. Always review the specific model's license before production use.